Context Engineering: Building Reliable AI Workflows with Real-World Context
Part 1 of a 3-part series from Agami on context engineering—the real engine behind reliable AI. We break down what it is, why it matters more than model choice, and how it powers production-scale outcomes.
Introduction
Tobias Lütke (Shopify’s CEO) first proposed “Context Engineering,” and Andrej Karpathy later amplified the idea prompting widespread discussion across the AI community. However, this time we are keen to lean into this phrase, since we see the Enterprise AI story being built most in this layer.
Since onboarding our first clients, Agami has consistently generated meaningful outcomes by building and refining a layer that we first called “Context Tuning”, (and patiently explaining to people why it’s not just prompt engineering). Since we’ve had a few battle tested experiences, this would be a good time to share our learnings from it.
In our three-part series, we’ll cover:
- Part 1 – Context Engineering - The Agami Definition (this post)
- Part 2 – Why Context Engineering always trumps choice of LLMs
- Part 3 – Build vs Buy: How to think through your options for Context Engineering
Who should read this
Business and tech leaders building and evaluating AI‑enabled workflows that need to drive production‑scale outcomes. Specifically, those business leaders who are worried about how long it's going to take to get something valuable done with AI.
Context Engineering - The Agami definition
Business processes are inherently static workflows - built to be stable, repeatable and scalable. But the real opportunity lies within the tasks, those critical steps where AI can make a decisive difference. The meeting summary that needs to feed into a report, or a powerpoint deck that needs to be created from 9 different data sources, that sentiment analysis that needs to run on a support ticket thread and escalate if it crosses a threshold.
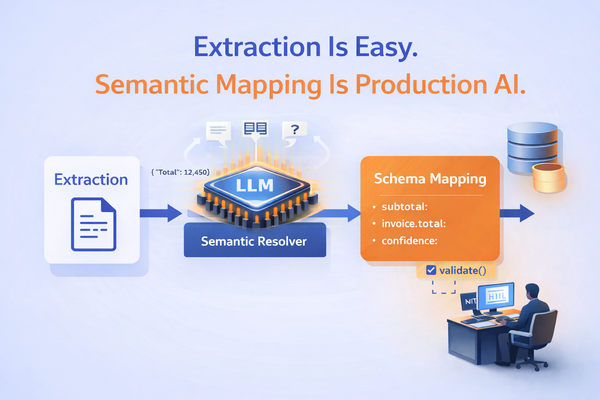
Context Engineering is intentionally constructing everything the model needs to fulfil those steps consistently and reliably.
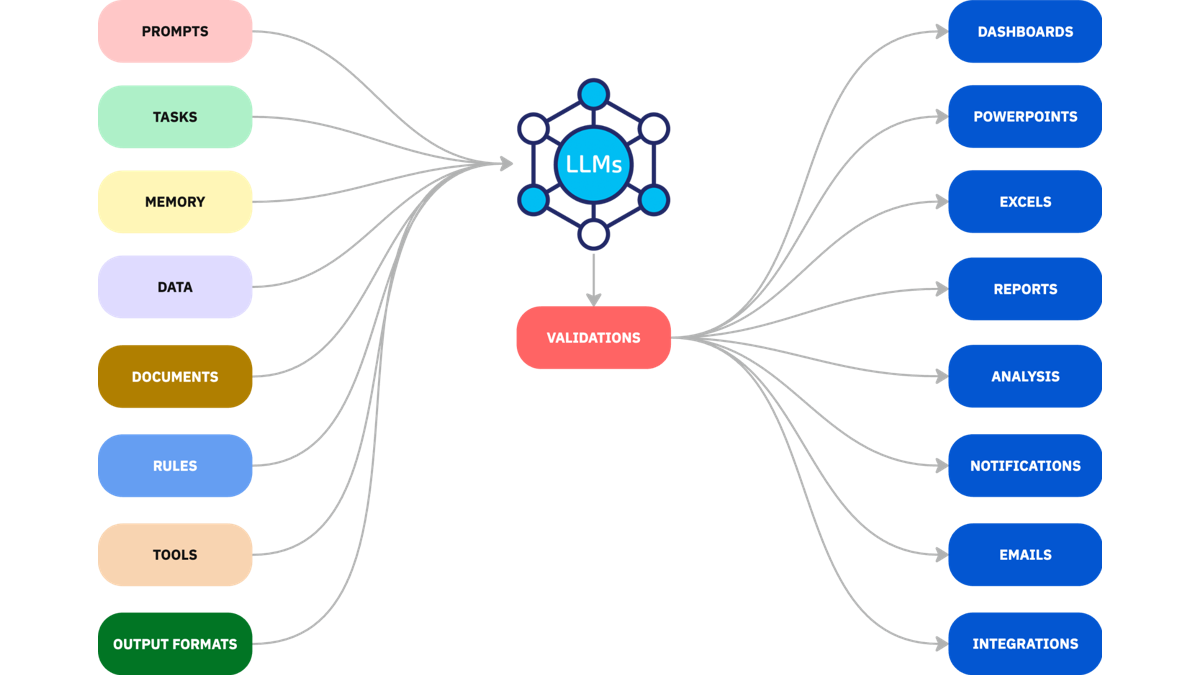
The core idea is that we build systems that dynamically assemble multiple layers of context - structured prompts, knowledge fragments, memory, tooling, and more, so the LLM can tackle real-world business challenges accurately and reliably.
Key Building Blocks of Context Engineering
While there are several versions of this, these are the core granular pieces that Agami has built and refined to enable reliable contextual layers for various use cases
- System-Level Instructions - Set the tone, guiding principles, and any guardrails. This establishes the LLMs behavior and its boundaries.
- Precise Task Definitions - Clearly state the objective: what is this step, and what makes the output right? Define metrics and criteria upfront.
- Few-shot Examples - Deliver sample inputs and ideal results to shape model expectations, enhancing consistency and outcome quality.
- Short-Term Memory Layer - Incorporate recent interactions or decisions so the AI understands current flow and avoids redundant follow-ups.
- Long-Term Memory Repository - Store dynamic data (user profiles, previous sessions, configurations, preferences, and archival decisions) and recall them when needed.
- Knowledge Retrieval - Dynamically pull relevant documents, SOPs, or policies into the context window (Knowledge Graph + RAG) to inform decisions - essential for factual accuracy.
- Tool & API Integration - Enable LLMs to trigger real actions - fetching live data, writing to databases, updating dashboards, or calling external services.
- Access Permissions - Ensure context respects data privacy and security policies defined for both your internal and external users.
- Structured Output & Delivery - Define how results should be formatted (e.g., JSON, HTML, CSV) and where they should go: CRM systems, email threads, downstream apps.
- Validation & Evaluation - Embed tests, consistency checks, business-rule validations, human-in-the-loop verification to reduce errors and hallucinations.
Use Case: PowerPoints from Excel + Narrative
Turning raw Excel data into polished, branded slide decks was a use case that multiple of our clients wanted. However, they wanted more than charts - they wanted the context layer to understand the KPIs and the relationships in the Excel sheet, tie it to internal documents that explain the KPIs, pull relevant external benchmarks from trusted sources, and a slide sequence that created the right visual narrative for the data that adhered to their fonts, colors, chart styles and sequence.
Before Context Engineering
You feed the Excel data into an AI model with some prompts to explain the data, and it spits out some basic slides which need further work (sometimes more than if the user was to start from scratch), pretty much defeating the purpose of injecting AI into the mix. You then try to stitch together a workflow using no code tools like n8n, or, if you're so inclined, hire a few engineers to put together the overall flow with prompt chaining and API integrations. But the output is never reliable, debugging it is complex, and, memory and preferences are hard to integrate into this workflow.
With Context Engineering
Here's everything the system captures and shapes:
- Excel Data Inputs: The spreadsheet data is structured and compressed into chart-ready segments from previous examples.
- Internal Narrative: The system retrieves relevant internal documents: strategy memos, past consultancy reports, insights from recent engagements using the Knowledge graph enabled RAG.
- External Trusted Sources: Benchmark reports or industry studies from news or analysts are pulled for market comparisons or validation. Sources white listed in your configurations.
- Chart styles - The user and firm preferences to apply the best chart to represent the visual narrative are enforced through learned previous interactions.
- Visual Style Rules: Presentation templates and style guides are enforced - colors, fonts, layouts, chart types - all aligned to the firm's standard defined within your output formats.
- Slide Narrative Layer: Key narrative bullet points, context snippets, and chart captions get generated to line up the data with storytelling.
- Validation & Review Rules: Checks ensure numbers match source Excel, narrative language follows firm tone, external data points are cited, and visuals follow layout rules.
Outcome: Slide decks that feel like they were hand-crafted by consultants: consistent branding, tight narrative, data-driven visuals, all delivered in minutes.
Why Context Engineering makes this work
Reliable outputs every time
Every presentation, slide, or insight feels trusted, intentionally designed to avoid hallucinations or unpredictable responses. Because we control not just the prompt but the context sources - internal docs, external benchmarks, memory slices, user preferences, which are validated before generation. The result is consistent quality, not a one-off lucky output.
In enterprise settings, structured retrieval and validation logic enable versioning, auditing, and scalable performance. That’s why startups in regulated sectors are shifting from prompt hacks to fully architected context workflows—because reliability demands structure.
Brand-aligned rigor, every time
In consulting or corporate use cases—slide decks, decision briefs, reports—style and content must follow brand voice, formatting standards, and internal logic. With context engineering, every slide not only draws from approved frameworks and firm methodologies, but also adheres to chart types, color palettes, language tone, and storytelling structures unique to your organization.
Rather than “winging it,” context engineering turns input data into outputs that feel like they were created in-house, preserving your firm’s intellectual property and enforced Brand in every AI interaction.
Context is the real deal
If there’s one thing to take away, it’s this: context engineering is the real backbone of reliable AI workflows. It’s not a one-time prompt or a clever hack - it’s an engineered (ergo - versioned, tested, enhanced, monitored) system that brings together data, documents, preferences, logic, and output structure in a way that makes LLMs truly useful.
What we’ve shared in Part 1 is our definition of context engineering, grounded in an actual production use. If you’re building anything more complex than a chatbot, this is the layer you’ll need to get right.
Up Next: Why Context Beats Model Choice
In Part 2, we’ll show how the same well-engineered context fed into multiple models produces the same (or very similar) results, and why a strong context layer matters more than picking the "best" LLM on the market.
Later: Should You Build or Buy?
In Part 3, we’ll walk through how to evaluate whether to build your own context stack or work with a platform like Agami. We’ll share what we’ve seen across industries, and the hidden costs (and pitfalls) of going it alone.
Want to see how Agami can help build the Context layer for your business? Book a demo →
Frequently Asked Questions (FAQ)
1. What is context engineering?
Context engineering is the process of assembling everything an AI model needs — data, documents, memory, tools, rules, and structure—so it can generate reliable, trustworthy, and repeatable outputs. It's what turns a prompt into a production-grade system.
2. How is it different from prompt engineering?
Prompt engineering focuses on crafting a single input to get a good response. Context engineering builds the full runtime environment: structured inputs, retrieval logic, tool access, validations, and output formatting. It's the difference between scripting a chatbot and deploying an intelligent agent.
3. Is this only relevant for large enterprises?
No. Any team building AI workflows—like generating presentations, summarizing reports, or extracting insights—can benefit. Smaller teams gain from reliability, brand alignment, and fewer surprises in output.
4. Do I still need the best LLM if I do context engineering well?
Not necessarily. A well-structured context layer often delivers better results than switching models. We'll cover this in Part 2, where we show the same context running across different LLMs with the same or very similar outputs.
5. Can context engineering reduce hallucinations?
Yes. With structured retrieval, tight access control, and validation layers, the model is only exposed to trusted information—dramatically lowering the risk of hallucinated content or off-brand language.
6. Should we build or buy our context infrastructure?
That’s what we’ll explore in Part 3. Building gives control, but it's time-consuming and expensive. Platforms like Agami give you a head start with enterprise-grade context orchestration, validation, and deployment tools out of the box.