Context Engineering, Part 3: Making Context Work
What does it take to make Context Engineering work in production? In Part 3, we break down the platform components, team setup, key pitfalls, and the real tradeoffs between building your own stack or buying a platform like Agami.
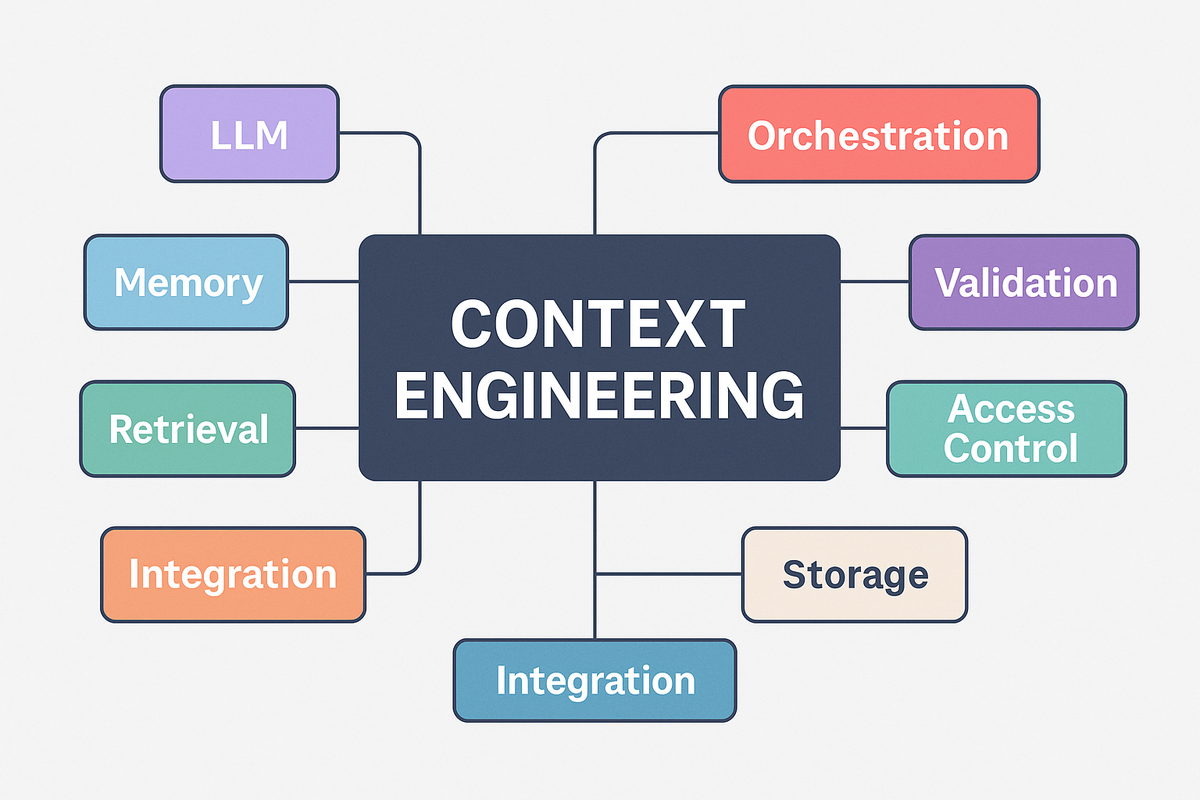
So, you’ve wrapped your head around what Context Engineering is, and you’ve seen why context trumps model choice. The natural next question: What does it actually take to put this into production? Should you build your own stack, or is it smarter (and faster) to buy? Let’s get pragmatic.
Quick refresher—what’s this series about?
- Part 1 – What is Context Engineering?
- Part 2 – Why Context Engineering matters more than your choice of LLM
- Part 3 – Making Content Engineering work for you (this post)
What does it take to build Solid Context?
Context engineering isn’t just another layer you bolt onto your AI stack. It’s the heart of making LLMs trustworthy and useful in real-world settings. It’s the foundation that ties together product thinking, robust engineering, business processes, and the ability to learn and adapt as your workflows (and models) change.
Like any other Software Engineering endeavor, it's an ongoing process: you’re never fully “done”. Every new workflow, every data source, every shift in your business or user needs could mean you’ll need to refine your context approach. If you treat context engineering as a one-off setup, you’ll end up with brittle, unreliable outputs. Treat it as a core, living part of your stack and you’ll unlock the real potential of AI in production.
Platform Options
When it comes to building or choosing a context engineering platform, you’re not starting from scratch. You’re choosing from an increasingly rich ecosystem of tools. Each layer of the stack has multiple open‑source and commercial options, and the right mix depends on your priorities: speed to market, flexibility, control, security, and long‑term maintainability.
Some teams prefer to hand‑pick every component and stitch them together; others want a platform that comes with these pieces pre‑integrated, tested, and ready to configure. Both paths can work, but they come with very different timelines, costs, and operational burdens.
Here’s a breakdown of the major components you’ll need to think about, and the most widely‑used options, open and closed source, for each:
| Component | Current Options (Open & Closed Source) |
|---|---|
| LLMs | Open source: OpenAI oss, Llama, Mistral, Falcon, Gemma Closed: OpenAI (GPT-4o, o3 etc), Anthropic (Claude), Google Gemini |
| Memory | Open source: Milvus, Chroma, Weaviate, FAISS, Qdrant Closed: Pinecone |
| Retrieval | Open source: LangChain, LlamaIndex, Haystack, custom code |
| Orchestration | Open source: LangChain, Semantic Kernel, Apache Airflow, custom code |
| Validation/Evaluation | Open source: DeepEval, Trulens, Promptfoo |
| Integration | Open source: n8n, microservices, API hooks Closed: Zapier, custom connectors |
| Access Control | Open source: Promptfoo, Open Policy Agent (OPA), Cerbos, OpenFGA, Keycloak, Authentik, Zitadel Closed: Okta, Custom RBAC/IAM, platform perms |
Who Actually Makes This Work?
Even the best LLMs won’t deliver value without the right team behind them. It’s a cross-functional effort that spans infrastructure, modeling, data, product, and operations.
To build a production-grade system that consistently delivers trusted, useful outputs, you’ll need more than prompt tweaks. You need roles that cover everything from retrieval and validation logic to monitoring and business alignment.
Here’s the core tech team setup we’ve seen work best (the assumption being that business teams are aligned behind the effort):
| Role | Why Critical |
|---|---|
| Backend/Fullstack Eng | Orchestrates APIs, context flow, integrations |
| ML/AI Engineer | Data preparation, LLM eval, prompt/retrieval/memory design |
| Data Engineer | Maintains datasets, embedding pipelines |
| Product Manager | Maps engineering effort to real business outcomes |
| QA/Test Engineer | Tests quality, on-brand outputs |
| DevOps/SRE | Infra, scaling, monitoring, security |
Success Factors (and Pitfalls)
It’s easy to get excited about the tech, but what really matters is process and people. Here’s what helps and what can trip you up:
What Helps You Succeed
- Strong process: Define, test, and iterate context for each business use case. Don't skimp on your evals. In fact, always start with designing the evals.
- Buy-in from business: The best context is built in partnership with domain experts, not just engineers. Make sure they are part of designing the evals, and part of the human testing loop.
- Monitoring: Catch drift, errors, and drop-offs in output quality. Do this as part of your model builds and part of the production output logs.
- Rapid iteration: Context changes as the business (and LLMs!) evolve. Make sure your context iterations are versioned. You want to be able to roll back or even A/B test different versions in production.
Where Teams Go Wrong
- Underestimating maintenance: Context engineering isn’t “set and forget.” You’ll need to tweak as data, workflows, and models change.
- Neglecting validation: Hallucinations and off-brand responses are a risk if validation/testing is skipped. Don't vibe-test your way through this. Have a real team and programmatic evals to test for accuracy.
- Siloed teams: Engineering, AI, and business must collaborate. Siloed efforts end up with fragile, untrusted outputs or worse - building something no one wants.
- Choosing tools by hype: Pick what you can support, something that fits into your existing tech stack, complementing the team skills that you have already invested in. Not just the latest shiny thing.
Build vs Buy: The Real Tradeoff
One of the biggest decisions you’ll face is whether to build your own stack or buy into a platform like Agami. This isn’t just a technical choice - it’s a strategic one that affects speed, cost, control, and long-term agility.
Let’s break it down clearly:
| Factor | Build | Buy |
|---|---|---|
| Flexibility | Maximum — tailor every component to your workflows | Platform-driven — limited but often opinionated configurations |
| Speed to Production | Slower — setup, integration, and testing take time | Faster — pre-integrated and ready-to-use components |
| Maintenance | Ongoing — your team maintains, upgrades, and troubleshoots | Vendor-handled — updates, fixes, and improvements included |
| Cost Structure | High upfront dev costs, lower variable over time | Subscription or licensing fees, lower initial investment |
| IP & Control | Full ownership of stack, data flow, and model behavior | Shared control — vendor/platform holds part of the IP logic |
| Security & Compliance | Custom enforcement of policies and data governance | Platform-defined controls, SOC2/ISO certifications |
| Team Requirements | Needs a full cross-functional team (Eng, AI, DevOps) | Can start lean; vendor handles complex infrastructure |
So… Which One?
If you have the team, the budget, the desire to hold full IP, and the need for deep customization, building your own context stack might make sense. But for most companies, buying a purpose-built platform like Agami means you get to production faster, with fewer headaches while retaining flexibility where it counts.
Think of it like this: building is for control, buying is for leverage. Choose based on what matters most to your business today and how fast you need to move.
Important Takeaways
- Context is non-negotiable: Reliable, on-brand, and production-grade AI needs more than just a strong model. Building and managing the context layer is where the real value (and effort) lies.
- Platform choice matters, but not as much as your process: Whether you build or buy, success depends on clarity of requirements, clean integration, and tight validation - not just which tool or vendor you pick.
- It’s a team sport: Effective context engineering needs a mix of backend, ML, data, QA, DevOps, product and (critically) business expertise. If you want to get value out of your "AI budget", then create a team that can help you win, rather than build toy prototypes.
- Monitor, iterate, repeat: Context, data, and workflows will keep evolving. Continuous testing and business alignment make the difference between “one good demo” and a real, sustainable solution.
- Private deployments are possible (and sometimes necessary): But be ready for real infra and security work—especially if compliance, data residency, or full control are priorities.
- Build vs Buy isn’t one-size-fits-all: If speed, stability, and rapid ROI are top priorities, platforms like Agami help you go further, faster. If you need ultimate control and have the resources, building your own stack may pay off long-term.
Closing Thoughts
There’s no universal answer, but if you want AI that really works for your business, context engineering isn’t optional, it’s the multiplier. Make sure you get it right, whichever path you choose.
If you’ve read this far, you’re already ahead of the pack. And if you want a head start, talk to Agami today by Booking a demo →
Frequently Asked Questions (FAQ)
1. What does it take to build a production-ready context engineering system?
You need more than just prompt engineering. It requires a full stack: LLMs, memory, retrieval, orchestration, validation, access control, and integration. And it needs to be backed by a cross-functional team covering backend, ML, data, DevOps, and product roles.
2. Should I build my own context stack or use a platform like Agami?
If your priorities are speed, stability, and faster ROI, buying a platform like Agami is smarter. If you need deep customization and full IP ownership—and have the team and budget—building might work. Most teams benefit from buying first, then layering in customization as they scale.
3. What are the key components of a context engineering stack?
The major components include: LLMs, memory/vector DBs, retrieval logic (RAG), orchestration layers, validation/evaluation tooling, access control, and integration with APIs or tools. Each has open and commercial tools available to plug into your architecture.
4. Can smaller teams implement context engineering effectively?
Yes. With the right platform and a lean team (or external partner), even smaller teams can implement context engineering. Buying instead of building reduces the need for a large in-house tech stack or specialist team upfront.
5. How do I keep my context stack reliable over time?
Context stacks need monitoring, evals, and ongoing iteration. Track quality drift, version your context changes, involve business teams in testing, and use eval frameworks to catch issues before they hit production.
6. Is private deployment of context engineering platforms possible?
Yes. For teams with regulatory, data privacy, or control needs, context platforms can be deployed privately. Just be aware of infra, security, and compliance work involved—especially if you're managing your own stack.
7. What’s the biggest mistake teams make when adopting LLMs?
Thinking the LLM alone is enough. Without a structured, validated, and evolving context layer, outputs become unpredictable. The real value comes from engineering the right context, not just picking the most powerful model.