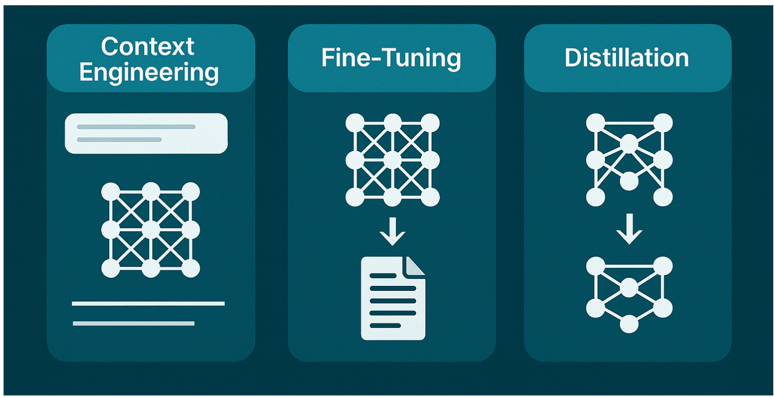
Context Engineering vs Fine-Tuning vs Distillation: How to Decide
Choosing between context engineering, fine-tuning, and distillation is key to making LLMs work in production. This guide explains each approach, when to use them, their trade-offs, and how to balance cost, accuracy, and scalability.
After we did our Context Engineering Series, we received feedback that we had not addressed two other key pieces of the puzzle that has business leaders scratching their heads:
- At what point do we decide that we should fine-tune a model or build our own foundational models?
- What is the difference between distillation and fine tuning and when should I choose one over the other?
The crux of the question being - what do we do on day zero? Where do we start? That’s where, this post is going to address three strategies dominating the conversation: context engineering, fine-tuning, and distillation.
In this post, we’ll unpack what these terms actually mean, how they differ, when to use each, and the typical costs you should expect on platforms like AWS, Azure, and GCP. Finally, we’ll leave you with a decision framework that makes the trade-offs easier to navigate.
What Do These Terms Mean?
Let's unpack the jargon.
Context Engineering
Context engineering is about shaping the input that goes into an LLM — without changing the model’s parameters.
Think of it as:
- Structuring prompts carefully (prompt engineering).
- Using retrieval-augmented generation (RAG) to bring in relevant context at query time.
- Adding tool orchestration (e.g. custom code, external APIs) to extend capabilities.
- Defining memory layers to persist important information across turns.
- Defining output formats that fit the workflow you are solving for.
- Defining guardrails and validations that govern the entire flow.
You don’t “retrain” anything. You just optimize how you present the problem to the foundational model your are using. At Agami, we are massive proponents of Context Engineering. In fact our 3-part series on Context Engineering is our most widely read set of blogs.
Example:
An insurance underwriting assistant built on Qwen3 that pulls policy documents via RAG, pulls borrower financials via their submitted documents, and formats them into structured prompts, and provides a summary. No weights are changed, but the workflow is engineered for reliability.
Fine-Tuning
Fine-tuning is the process of modifying a pre-trained LLM’s internal weights so that it performs better on a specific domain or task. Instead of starting from scratch, you build on top of a base model’s general knowledge by teaching it new patterns with curated data.
How Fine-Tuning Works
There are two main approaches:
- Full Fine-Tuning
This involves updating all the parameters of the base model. It gives maximum flexibility and accuracy, but for large models with billions of parameters, it’s usually impractical. Training can take thousands of GPU hours and cost tens of thousands of dollars — not to mention the need for large, high-quality labeled datasets. - Parameter-Efficient Fine-Tuning (PEFT)
Techniques like LoRA (Low-Rank Adaptation), prefix tuning, or adapters allow you to update only a small subset of the model’s weights while freezing the rest. This drastically reduces compute costs and training time while still achieving strong domain adaptation. LoRA, for example, has become the industry standard for enterprises that want the benefits of fine-tuning without the overhead.
Why Fine-Tuning matters
Context engineering can take you far, but it has limits. If the base model doesn’t “understand” the nuance of your domain — the jargon, reasoning style, or strict precision required — no amount of prompt shaping will consistently close the gap. Fine-tuning directly bakes that domain knowledge into the model.
This makes it especially valuable when:
- Your domain has specialized vocabulary or concepts (e.g., medical imaging, financial derivatives, pharmaceutical trial design).
- You require high-accuracy classification or structured outputs.
- The cost of wrong answers is high (e.g., legal advice, regulatory compliance).
- Latency is a concern, since a fine-tuned model often needs less prompt context than a RAG-heavy setup.
Examples in Practice
- Healthcare: Google’s Med-PaLM 2 was fine-tuned on curated medical datasets, enabling it to achieve physician-level accuracy on US medical licensing exam questions. This kind of reliability is critical in life-or-death applications.
- Legal Tech: Startups are fine-tuning base models on millions of contracts to recognize clauses, risks, and obligations with extremely high precision, something generic LLMs often miss.
- Financial Services: Hedge funds fine-tune models on proprietary analyst notes and structured filings to improve accuracy in sentiment classification and forecasting tasks.
Distillation
Distillation, or knowledge distillation, is the process of training a smaller “student” model to replicate the behavior of a larger “teacher” model. Instead of learning directly from raw human-labeled data, the student learns from the teacher’s outputs (its probability distributions, also known as soft labels).
This makes it possible to compress the intelligence of a large model into a smaller, faster one — reducing inference cost and latency while preserving most of the accuracy.
How Distillation Works
- Teacher Model: A large, accurate LLM (e.g., GPT-4, LLaMA-70B) generates outputs on a training dataset.
- Student Model: A smaller model (e.g., 7B parameters) is trained to mimic the teacher’s outputs.
- Optimization: The student learns not just the correct answers, but the probability distribution over possible answers — giving it a richer sense of the teacher’s reasoning.
Why Distillation Matters
LLMs are often too heavy for production-scale use cases. Running GPT-4 or LLaMA-70B on every query may cost dollars per interaction and introduce unacceptable latency. Distillation gives you a production-friendly model that is:
- Smaller
- Faster
- Cheaper to run
while retaining most of the teacher’s capabilities.
Examples in Practice
- DistilBERT: Hugging Face’s distilled version of BERT — 40% smaller, 60% faster, with 97% of BERT’s performance. It made BERT feasible for mobile and real-time applications.
- OpenAI Whisper variants: Distilled into smaller models to run on edge devices like smartphones while still transcribing speech effectively.
- Enterprise Assistants: Companies distill fine-tuned models into smaller students to deploy within on-prem servers or low-cost GPU clusters without sacrificing too much accuracy.
The Key Differences at a Glance
| Feature | Context Engineering | Fine-Tuning | Distillation |
|---|---|---|---|
| Changes model weights? | ❌ No | ✅ Yes | ✅ Yes (new model) |
| Data needed? | Minimal (docs, prompts) | Domain-specific labeled data | Outputs from a teacher model |
| Cost | Very low | High | Moderate |
| Speed to deploy | Fast | Slow | Medium |
| Best for | Flexibility, rapid prototyping, well defined narrow use cases. | Accuracy, domain-specific performance | Efficiency, scaling, deployment to edge |
Trade-offs: Context Engineering vs Fine-Tuning vs Distillation
Every approach comes with strengths and limitations. Choosing the right one depends on what you’re optimizing for — speed, accuracy, or efficiency.
Context Engineering
- ✅ Fast to Deploy: No model retraining needed — you can ship use cases quickly.
- ✅ Low Cost: Costs are tied to tokens and API usage, not expensive GPU training runs.
- ✅ Highly Flexible: Easy to iterate with new prompts, retrieval sources, and workflows.
- ❌ Ceiling on Accuracy: If the base model lacks domain understanding, context alone won’t bridge the gap.
- ❌ Prompt Overhead: Adding too much context inflates token cost and latency.
- ❌ Fragility: Minor changes in prompts or retrieval quality can cause inconsistent outputs. Focus is on designing a strong evals framework.
Fine-Tuning
- ✅ High Accuracy: Embeds domain-specific knowledge into the model itself.
- ✅ Reduced Prompt Length: Since the model “knows” the domain, less context is needed per query.
- ✅ Consistency: Outputs are less sensitive to prompt wording.
- ❌ High Cost: Training large models or even LoRA adapters requires significant GPU time and expertise.
- ❌ Maintenance Burden: Needs periodic re-training as the domain evolves.
- ❌ Risk of Overfitting: A narrow dataset can reduce generalization outside your use case.
Distillation
- ✅ Efficient Inference: Smaller models run faster, with lower GPU memory and compute needs.
- ✅ Lower Cost at Scale: Perfect for high-volume queries where inference cost dominates.
- ✅ Scalable Deployments: Easier to run on edge devices or smaller servers.
- ❌ Accuracy Loss: Student models rarely match the teacher’s full performance.
- ❌ Upfront Training Cost: Requires running large teacher models to generate outputs.
- ❌ Dependent on Teacher Quality: If the teacher isn’t well-adapted to your domain, the student won’t be either.
The Big Picture
- Context Engineering → Best for speed and cost when starting out.
- Fine-Tuning → Best for accuracy and reliability in specialized domains.
- Distillation → Best for efficiency and scale once accuracy is good enough.
Together, these three approaches form a progression path:
Context Engineering → Fine-Tuning (if accuracy is needed) → Distillation (to scale efficiently).
When to Apply Each: Real-World Examples
When to Use Context Engineering
Use this when:
- You’re starting out with a new use case.
- You don’t have large labeled datasets.
- You want to keep costs low and iterate quickly.
Example:
A consulting firm deploys an AI assistant to summarize industry reports. Instead of fine-tuning, they use context engineering with RAG: the assistant fetches relevant sections and inserts them into prompts. The result is accurate, low-latency summaries without retraining.
When to Use Fine-Tuning
Use this when:
- Accuracy is your top priority.
- You have proprietary, high-quality labeled data.
- Context engineering alone can’t capture the nuance.
Example:
A legal AI company builds a clause classifier. Context engineering helps for basic summaries, but to reach the 99%+ precision needed for contract review, they fine-tune a base model on millions of labeled clauses.
When to Use Distillation
Use this when:
- Latency and cost are the bottlenecks.
- You’ve validated the workflow with context engineering.
- Accuracy is good enough, but inference is too slow or expensive.
Example:
An e-commerce company deploys a shopping assistant. The full LLaMA-70B works well, but inference costs are unsustainable. They distill it into a smaller 7B student model that runs at 5x lower cost with only a small dip in accuracy.
A Practical Strategy for Teams
Here’s how most enterprises should think about the decision:
- Start with Context Engineering.
It’s the fastest, cheapest, and most flexible way to validate whether an LLM can handle your use case.- Add retrieval.
- Design prompts carefully.
- Layer in memory and tools.
- If accuracy is high but latency/cost is unsustainable → Distillation.
Once the workflow is validated, train a smaller student model to bring down compute costs and make deployments scalable. - If accuracy is lagging despite good context → Fine-Tuning.
Bring in domain-specific data. Use LoRA/PEFT methods first, as they’re cheaper than full fine-tuning. Only go all-in on full fine-tuning if mission-critical accuracy demands it. - Hybrid Approach.
Fine-tune for accuracy, then distill the fine-tuned model to optimize inference cost.
This flow lets you balance speed, cost, and performance at different stages of maturity.
The Cost Dimension: AWS, Azure, and GCP
One of the biggest questions teams ask: what will this cost me?
Here’s a view across the three major cloud providers:
AWS
- Fine-tuning on Bedrock: You’re billed by compute time and tokens processed. Commonly used instances for heavyweight fine-tuning (such as p4d.24xlarge with 8xA100 GPUs) cost about $24–$40/hr. For model-specific training (e.g., fine-tuning Claude 2 or Llama 2), on-demand rates range $21–$40/hr per instance. The fine-tuning fee itself is typically $0.0004 per 1,000 tokens processed. Managed service add-ons or provisioned throughput (for inference) are additional.
- Distillation: Costs include both “teacher” model inference (typically using high-cost models) and training a smaller “student” model using those outputs. This is done at customization pricing, which is similar to fine-tuning rates. The key saving comes in post-distillation inference: uses much cheaper, “student” model pricing.
- Context engineering (RAG, prompt engineering, etc.): Costs are tied to API usage, compute for embedding/vector queries, and occasionally for running retrieval models (like rerankers or guardrails). This frequently comes out <$1,000 for robust MVPs.
Azure
- VM pricing for fine-tuning: The ND A100 v4 (8x A100/80GB GPUs) is $32.77/hr in the “East US” region. Per-GPU cost is $4.10/hr. Large multi-GPU jobs (complex LLMs) can easily run to $10,000–$50,000+ for full-scale fine-tuning on big data.
- Managed fine-tuning (PEFT/LoRA): Azure now offers managed/parameter-efficient tuning services—these typically cost much less (often $1,000–$5,000 for smaller jobs) and are accessible to startups.
- Distillation: Similar to AWS—there’s an up-front training cost for generating student data and model training, but massive downstream savings in inference costs.
- Context engineering (RAG, prompt chaining): Azure Cognitive Search and managed vector search are integrated; budget for API and data volume—real-world systems often stay under $1,000 to deploy.
GCP
- GPU pricing:
- Sustained use/committed discounts: You can achieve 25–30% savings with continuous use.
- Fine-tuning: Similar to others; full-finetune jobs (multi-GPU, multi-epoch) typically cost $10,000–$50,000 for large LLMs.
- LoRA/PEFT and distillation: Costs start as low as $1,000–$5,000 for smaller models/jobs; distillation setup costs are typically $5,000–$15,000, but inference cost is drastically reduced.
- Context engineering: Vector DB, basic embedding/gen AI infra, and API usage, well under $1,000 for feature-complete enterprise RAG.
Ballpark Estimates
- Context engineering: <$1K to build all the layers needed for a solid MVP.
- Fine-tuning (full): $10K–$50K+ depending on dataset size and epochs.
- LoRA / PEFT: $1K–$5K, more feasible for startups.
- Distillation: ~$5K–$15K upfront, but saves 50–80% in inference costs over time.
The Agami Recommendation
At Agami, our rule of thumb is simple:
- Always start with context engineering. It’s the foundation.
- Move to distillation if cost/latency become blockers.
- Fine-tune only if accuracy is mission-critical and you have the data.
This sequence minimizes risk, controls spend, and ensures your AI system scales gracefully from prototype to production.
Conclusion: A Framework to Decide
To wrap it up, here’s a one-line framework you can keep in mind:
- Need fast results, no data? → Context Engineering.
- Need higher accuracy, and have data? → Fine-Tuning.
- Need lower cost/latency, accuracy is “good enough”? → Distillation.
In practice, the journey usually looks like:
Context Engineering → (if accuracy needed) Fine-Tuning → (for cost/scale) Distillation.
By treating these as complementary stages instead of competing techniques, you can extract the most value from LLMs while keeping budgets and reliability in check.
Want to see how Agami can help simplify this journey for you? Talk to us today by Booking a demo →
Frequently Asked Questions (FAQ)
1. What is the difference between context engineering, fine-tuning, and distillation?
Context engineering shapes inputs (prompts, RAG, tools) without changing model weights. Fine-tuning adjusts the model’s parameters with domain data for higher accuracy. Distillation trains a smaller student model to mimic a larger teacher model for faster, cheaper inference.
2. When should I use context engineering?
Start with context engineering when testing new use cases. It’s fast, cost-effective, and flexible. Use it to validate whether an LLM can solve your problem before investing in fine-tuning or distillation.
3. When should I use fine-tuning?
Fine-tuning is ideal when accuracy is the top priority and you have quality labeled data. It works best in specialized domains like healthcare, legal, or finance where general-purpose models lack precision.
4. What are the benefits of distillation?
Distillation reduces latency and cost by compressing a large model into a smaller one. It’s best when you already have acceptable accuracy but need efficiency for large-scale or real-time deployment.
5. How much does fine-tuning or distillation cost on AWS?
On AWS, fine-tuning through Bedrock is priced by GPU instance hours (p4d or p4de can be $32–$40/hr) plus service fees. Full fine-tuning may cost $10K–$50K+. Parameter-efficient tuning (LoRA/PEFT) is cheaper, often $1K–$5K. Distillation requires teacher outputs + training, typically $5K–$15K upfront.
6. How much does fine-tuning or distillation cost on Azure?
On Azure, fine-tuning uses VMs like ND A100 v4 (~$32/hr for 8x A100 GPUs). Full fine-tuning can run tens of thousands of dollars depending on data size. LoRA-based tuning may cost a few thousand. Distillation has similar costs to AWS, but inference savings accumulate quickly at scale.
7. How much does fine-tuning or distillation cost on GCP?
On GCP, TPU v4 chips start at ~$8/hr and A100 GPUs range $2.9–$5.2/hr. Full fine-tuning may cost $10K–$30K+. With sustained-use discounts (~30%), costs can be reduced. Distillation typically costs $5K–$15K to train but delivers major long-term inference savings.
8. Should I always fine-tune before distillation?
Not always. A common strategy is: start with context engineering → fine-tune if accuracy is lacking → distill for efficiency. If accuracy is already high, you can skip fine-tuning and distill directly for efficiency.
9. Which approach is best for smaller teams?
Smaller teams should begin with context engineering since it requires minimal setup and cost. With platforms like Agami, even lean teams can implement robust context stacks. Fine-tuning and distillation can come later once ROI is proven.