Distilling a High-Performance Language Model
How Agami turned a large, costly AI model into a lean, production-ready asset for enterprise use.
Enterprise AI projects with private LLMs often start with massive, general-purpose models. They’re powerful but expensive:
- Multi-second latency per query
- Thousands of tokens consumed
- High infrastructure cost
That’s fine for a prototype, but not for real-time, highly used, cost-sensitive applications.
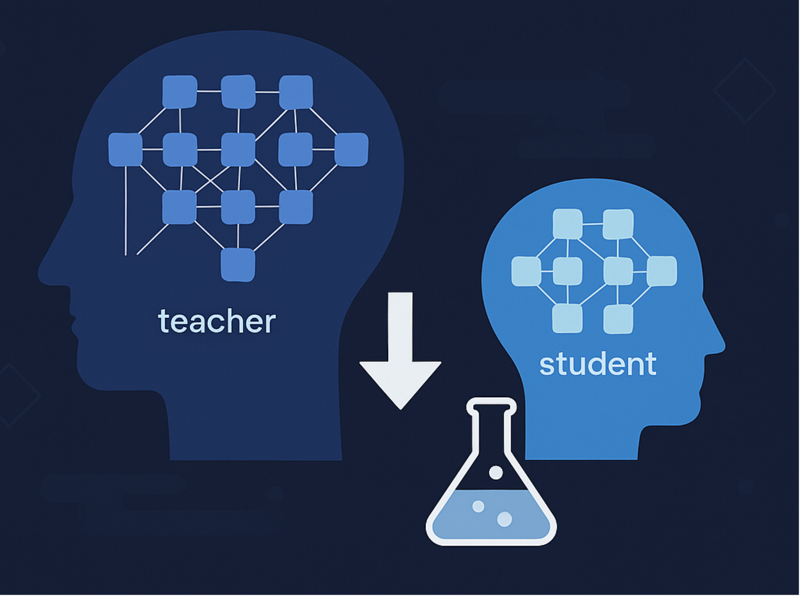
Knowledge distillation solves this. It’s the process of teaching a smaller “student” model to mimic a larger “teacher” model. Done right, the student keeps the teacher’s accuracy but runs faster and cheaper.
In a previous blog, we talked about the differences between Context Engineering, Fine-Tuning and Distillation and how to decide which approach to pick.
This post focuses on what we’ve seen as the more common path: using distillation after context engineering has improved accuracy, but left the system costly and slow.
Our Use Case
Our financial analysis app needed to handle four core tasks every time a user asked a question:
- Query classification → Decide which of 10 query types we were dealing with.
- Named entity recognition → Pull out the right financial entities and metrics (e.g., Amazon, Revenue, Net Sales, Growth rate).
- Currency identification → Catch whether a query was asking in explicit terms (“EBITDA of over $100m”) or implicitly (“How many unicorns did AI create since 2023”).
- Date range identification → Parse time references, both clear (“2020–2025”) and fuzzy (“post-Covid,” “last few quarters”).
Each of these ran as a separate LLM call with heavy context — prompts, examples, user preferences, and memory.
Quick aside: why not combine them into one giant prompt? Because smaller, focused tasks consistently yield higher accuracy. (We’ll unpack that in another post.)
The results were great on accuracy — our proprietary teacher model consistently hit >95%. But the cost was real: multi-second latency per query and thousands of tokens burned each time. With the app on track for thousands of MAUs and these four tasks at the heart of every spike, the economics didn’t work.
That’s where distillation — specifically Multi-task Knowledge Distillation (MKD) became the obvious path. One smaller student model trained to handle all four tasks meant we could keep accuracy while slashing latency and cost.
Step 0: Choosing the Student Model
Before any data prep or fine-tuning, the first decision was: which model should play the “student”?
We chose Llama 3.1 (8B) because it struck the right balance across four factors:
- Strong base performance: good general capabilities out of the box
- Ecosystem maturity: well supported across Hugging Face, Unsloth, and deployment toolchains
- Right size tradeoff: small enough to optimize for latency and cost, but large enough to capture domain-specific complexity
- Quantization readiness: proven to handle 4-bit quantization without significant accuracy loss, enabling efficient deployment on commodity GPUs
This choice set the foundation: rather than chasing the “newest” or “biggest,” we picked the model with the best balance of accuracy, efficiency, and portability.
Here are a few other models that are also great choices for student models - Qwen's family of models, DeepSeek-R1, OpenAI's GPT-OSS-20B and the Mistral small and medium models.
Step 1: Building the Dataset
The student model needed a clean “textbook” to learn from. We built it in five stages:
- Curated prompts from our financial domain
We started with real user queries and edge cases from our financial analysis workflows. This gave us a solid, domain-specific base that reflected how people actually ask questions. - Augmented them with synthetic variations
To avoid overfitting to a narrow set, we generated thousands of controlled variations — rephrasings, synonyms, number changes, and time period shifts. This expanded coverage and improved generalization. - Ran them through the teacher to generate gold labels
The teacher model produced the “answers” for each input. These outputs served as high-fidelity training labels for the student, carrying the same reasoning and formatting patterns. - Spot-checked outputs with Human-in-the-Loop (HITL)
We didn’t just trust the teacher blindly. Our team sampled and reviewed outputs, ensuring that the labels were both correct and consistent across tasks. This HITL cycle caught subtle errors before they propagated. - Standardized everything into consistent JSON
Teacher outputs varied — sometimes a string, sometimes a list, sometimes nested JSON. We normalized everything into a uniform JSON schema. This was critical: without it, the student would have inherited messy, inconsistent patterns.
{"input": "Top 5 tech brands by net profit", "task": "query_classifier", "output": "{\"category\": \"LIST\"}"}
{"input": "List Indian startups with more than ₹1,000 crore in ARR", "task": "currency_identifier", "output": "{\"currency\": \"INR\", \"symbol\": \"₹\"}"}
{"input": "Sales trend over the last 7 fiscal years", "task": "date_interpretation", "output": "[{\"phrase\": \"last 7 fiscal years\", \"date_period\": \"FY\"}]"}```
This final output jsonl file (an example snippet above) was the outcome of a rigorous process that ensured the student model trained on a large, clean, and predictable dataset.
Step 2: Efficient Fine-Tuning
Training a model with 8 billion parameters from scratch would have required huge infrastructure, weeks of GPU time, and hundreds of thousands of dollars. That was infeasible. Our goal was to achieve the same specialization without retraining everything.
LoRA Adapters (Low-Rank Adaptation)
Instead of updating all 8B parameters, we only trained a set of lightweight “adapter layers” plugged into the model’s architecture. This meant:
- <1% of parameters were updated
- Training became faster and cheaper
- The final output wasn’t a bulky 16GB checkpoint, but a few hundred MB adapter file
- We could swap adapters to specialize the same base model for different tasks (query classification vs. entity extraction, etc.) without retraining everything. To put it simply, we could have the student model become smart at multiple things instead of one single thing.
For enterprises, this translates to lower cost of experimentation and the ability to roll out multiple domain-specific models quickly.
Unsloth for Training Efficiency
Even with LoRA, fine-tuning an 8B model still strains GPU memory. Loading it in standard 16-bit precision requires ~16GB VRAM just to fit the weights, leaving no room for training.
Unsloth solved this in two ways:
- 4-bit Quantization: Shrinks memory footprint by ~75%, so the model fits on widely available GPUs (consumer or cloud). Importantly, this reduction came without measurable accuracy loss on our structured financial tasks.
- Optimized Kernels: Replaces standard PyTorch ops with custom Triton kernels, yielding 2–5× faster training iterations. If you ignore the jargon in the previous sentence, it means you get an output model faster.
from unsloth import FastLanguageModel
model, tokenizer = FastLanguageModel.from_pretrained(
"meta-llama/Meta-Llama-3.1-8B",
load_in_4bit=True,
max_seq_length=2048,
)
For any team looking to fine-tune modern LLMs, Unsloth is a powerful accelerator that we highly recommend. You can find their work on their official GitHub repository.
Step 3: Smarter Evaluation
Once the student model was trained, the question became: how do we prove it’s good enough to replace the teacher?
A simple “pass/fail” accuracy score wasn’t enough. Our tasks required structured outputs (JSON objects, entity lists, time ranges). A brittle exact match check would wrongly flag valid answers as failures. We needed an evaluation framework that was both rigorous and fair.
Semantic JSON Matching
For tasks where the model produced JSON, a naive string comparison failed on harmless formatting differences (like whitespace or key order). We instead compared the parsed objects semantically. Something as simple as -
import json
def semantically_equal(j1, j2):
return json.loads(j1) == json.loads(j2)
# {"currency": "INR", "symbol": "₹"}
# vs {"symbol":"₹","currency":"INR"} → True
This ensured our accuracy metrics reflected real correctness, not formatting quirks.
Partial Credit for Multi-Entity Outputs
In entity recognition, the model often outputs lists. A binary score would punish it unfairly if it got 2 out of 3 correct. We used intersection-over-ground-truth scoring to give partial credit.
import json
def calculate_entity_score(ground_truth_list_str, model_output_list_str):
try:
ground_truth = set(json.loads(ground_truth_list_str))
model_output = set(json.loads(model_output_list_str))
return len(ground_truth & model_output) / len(ground_truth) if ground_truth else (1.0 if not model_output else 0.0)
except:
return 0.0
# Example:
ground_truth = '["Jio", "Airtel"]'
model_output = '["Jio", "Airtel", "Vodafone"]' # Model found extra entities
# The score would be 2 (intersection) / 2 (ground truth) = 1.0 (Full credit)
# calculate_entity_score(ground_truth, model_output) -> 1.0
This highlighted genuine progress across model iterations, rather than treating “almost right” the same as “totally wrong.”
Task-Specific Benchmarks
- We benchmarked performance across all four key tasks:
- Query classification
- Named entity recognition
- Currency Identification
- Date range interpretation
For each, we compared the distilled student against both the teacher (high bar) and the raw base Llama model (low bar). The student’s accuracy consistently matched the teacher, proving distillation worked.
This evaluation framework gave us:
- Trustworthiness → Decision-makers could see that accuracy wasn’t just “close,” it was measured rigorously and fairly.
- Nuanced KPIs → Engineering teams could track improvements over time instead of relying on blunt accuracy.
- Confidence to deploy → The model didn’t just “feel” good enough; it was measured good enough.
Step 4: Deployment Lessons
Distillation isn’t finished until the model runs reliably in production. Here are the key lessons we learned:
- Portability is essential
Always keep a clean, high-precision checkpoint as the “master.” From there, convert into the right formats for your environment: GGUF/Ollama for edge, Transformers/vLLM for servers. This avoids lock-in and ensures smooth transitions between platforms. - Quantization is environment-dependent
4-bit quantization shrank our model by ~75% without hurting accuracy on structured tasks. For cloud GPUs with abundant memory, 8-bit or 16-bit may be simpler. For edge or low-VRAM servers, 4-bit is what makes deployment feasible. - Rollouts should be gradual
Don’t flip the switch overnight. Run the student alongside the teacher (shadow traffic), then roll out incrementally. This builds confidence that accuracy and safety hold up under real workloads. - Versioning and governance matter
Every release should track the base model, adapter, quantization level, tokenizer, and evaluation metrics. Carry forward safety filters from teacher to student to avoid regressions.
Before vs After: Teacher Model vs Distilled Student
| Metric | Teacher (Baseline) | Distilled Llama3.1-8B | Improvement |
|---|---|---|---|
| Accuracy | ~95% (on core tasks) | ~95% (matched teacher) | ✅ Maintained |
| Latency | 2–3 seconds / query | <1 second / query | ~60% faster |
| Model Size | ~16 GB | Few hundred MB (adapter) | 50× smaller |
| Cost / Query | High (multi-thousand tokens, GPU heavy) | Low (sub-thousand tokens, efficient inference) | >70% cheaper |
Final Takeaways
Knowledge distillation turned our large, expensive model into a lean, production-ready asset without compromising accuracy. The journey taught us a few clear lessons that apply to any enterprise AI team:
- Start with the right student model → ecosystem support, quantization readiness, and size tradeoffs matter more than chasing the latest release.
- Data quality is everything → standardized, consistent outputs are the foundation for a reliable student.
- Efficient fine-tuning unlocks feasibility → LoRA adapters and quantization make billion-parameter models trainable on commodity hardware.
- Measure what matters → semantic evaluation and partial credit scoring build trust in real performance.
- Deployment is where success is proven → portability, rollout safety, and governance ensure models move from lab to production smoothly.
Distillation is more than a technical trick — it’s a practical lever for enterprises to cut cost, reduce latency, and expand deployment options, all while keeping accuracy intact.
Frequently Asked Questions (FAQ)
1. What is multi-task knowledge distillation (MKD)?
Multi-task knowledge distillation trains one smaller student model to handle multiple related tasks at once (e.g., query classification, NER, currency, and date detection). This reduces the number of large model calls, cutting latency and cost while maintaining accuracy.
2. Why is knowledge distillation important for enterprise AI?
Enterprises need AI that is accurate, fast, and cost-effective. Knowledge distillation lets teams compress large, expensive teacher models into smaller student models that can run in real time, on lower-cost hardware, and even at the edge.
3. What models are good candidates for student models?
Strong student candidates balance performance, tooling support, and quantization readiness. Examples include Llama 3.1 (8B), Qwen family models, DeepSeek-R1, OpenAI GPT-OSS, and Mistral small/medium models.
4. Does quantization reduce accuracy?
With modern techniques like 4-bit quantization, accuracy loss is minimal or negligible for structured tasks such as classification, entity recognition, and financial analysis. It reduces model size by ~75%, enabling deployment on commodity GPUs or edge devices.
5. How does distillation compare to fine-tuning?
Fine-tuning improves accuracy by adjusting model weights for a domain. Distillation focuses on efficiency—compressing a large teacher into a smaller student with comparable accuracy. Many enterprises use both: fine-tune first for accuracy, then distill for speed and cost savings.
6. How much does distillation cost?
Costs depend on data size and infrastructure. Typical enterprise-scale distillation projects range from $5K–$15K in training compute, but the long-term savings from lower inference costs and faster response times far outweigh the upfront investment.
7. Can distillation help with edge deployment?
Yes. Distilled and quantized models are small enough to run on devices with limited compute or memory. This makes them ideal for low-latency use cases at the edge, or in environments where cloud access is restricted.
8. What are the risks of distillation?
Risks include inheriting errors or biases from the teacher model, and losing accuracy if the dataset or evaluation pipeline is not rigorous. Human-in-the-loop checks and semantic evaluation frameworks mitigate these risks.
9. When should an enterprise consider distillation?
Distillation is the right choice when accuracy is already high but cost and latency are bottlenecks. It’s especially valuable when scaling to thousands of users, running real-time applications, or preparing models for production deployment.