Document Processing - The Mapping Problem
Semantic mapping turns extracted data into reliable system state. Learn how to build, evaluate, and productionize it.
If you’ve built document pipelines in production, and you've read our previous blogs - you already know this:
- Extraction gives you text.
- Validation checks consistency.
- But your business runs on schemas.
Your databases expect:
invoice.total_grossinvoice.tax_amountfinancials.revenue_from_operationsfinancials.other_incomefinancials.ebitdafinancials.pat
This is the missing and often boring layer in most Document AI write-ups:
Semantic mapping: Which is correctly translating extracted labels + context into the canonical schema your databases expect.
This is where you'll end up investing significant amount of engineering efforts since your business users care about it. And where evals are going to matter most.
What “Schema Mapping” Really Means
People often imagine mapping as a dictionary:
"Total"→invoice.total
In reality, the same phrase can mean different things depending on context:
- “Total” might be:
- subtotal (pre-tax)
- total (post-tax)
- total due (after adjustments)
- grand total (including shipping)
- “Revenue” in statements might be:
- revenue from operations
- total income (includes other income)
- net sales
- gross revenue
So mapping is not a string or regex match - as much as Claude Code and Codex might try to push you towards it in your vibing sessions. It is a semantic resolution problem.
You need to infer:
- Which internal field this corresponds to
- With what confidence
- With what supporting evidence (for audit/HITL)
- Whether business rules agree
Two Concrete Examples
Example A: Financial Statements (Classic Ambiguity)
Extracted fields (from a P&L PDF)
{
"Total Income": "1,245,000",
"Revenue from Operations": "1,180,000",
"Other Income": "65,000",
"Operating Profit": "245,000",
"EBITDA": null,
"Net Profit After Tax": "182,000",
"Period": "FY2023",
"Currency": "INR"
}
Your internal schema might have:
financials.revenue_from_operationsfinancials.revenue_totalfinancials.other_incomefinancials.ebitdafinancials.ebitfinancials.pat
Once you've done your validations, you've answered the question - "Did we extract the numbers". What comes next is -
- Should
Total Incomemap torevenue_total? - Should
Operating Profitmap toebitorebitda? - If
EBITDAis missing, can it be derived? - If both “Revenue from Operations” and “Total Income” exist, do they reconcile with “Other Income”?
This needs semantic mapping + rules, not just schema validation.
Example B: Invoices (Less Ambiguity, More Edge Cases)
Extracted fields (from an invoice PDF)
{
"Invoice Number": "INV-1093",
"Total": "12,450.00",
"Tax": "1,245.00",
"Subtotal": "11,205.00",
"Discount": "0.00",
"Line Items": [
{"Description": "Consulting", "Amount": "11,205.00"},
{"Description": "GST 12%", "Amount": "1,245.00"}
]
}
Even here, mapping breaks when:
- Vendor uses “Total” to mean subtotal
- Tax includes cess/TDS/withholding adjustments
- Some invoices show “Amount Payable” vs “Grand Total”
- Discounts are already applied to line items but also shown as a separate field
Again: semantic mapping is required with evidence & confidence.
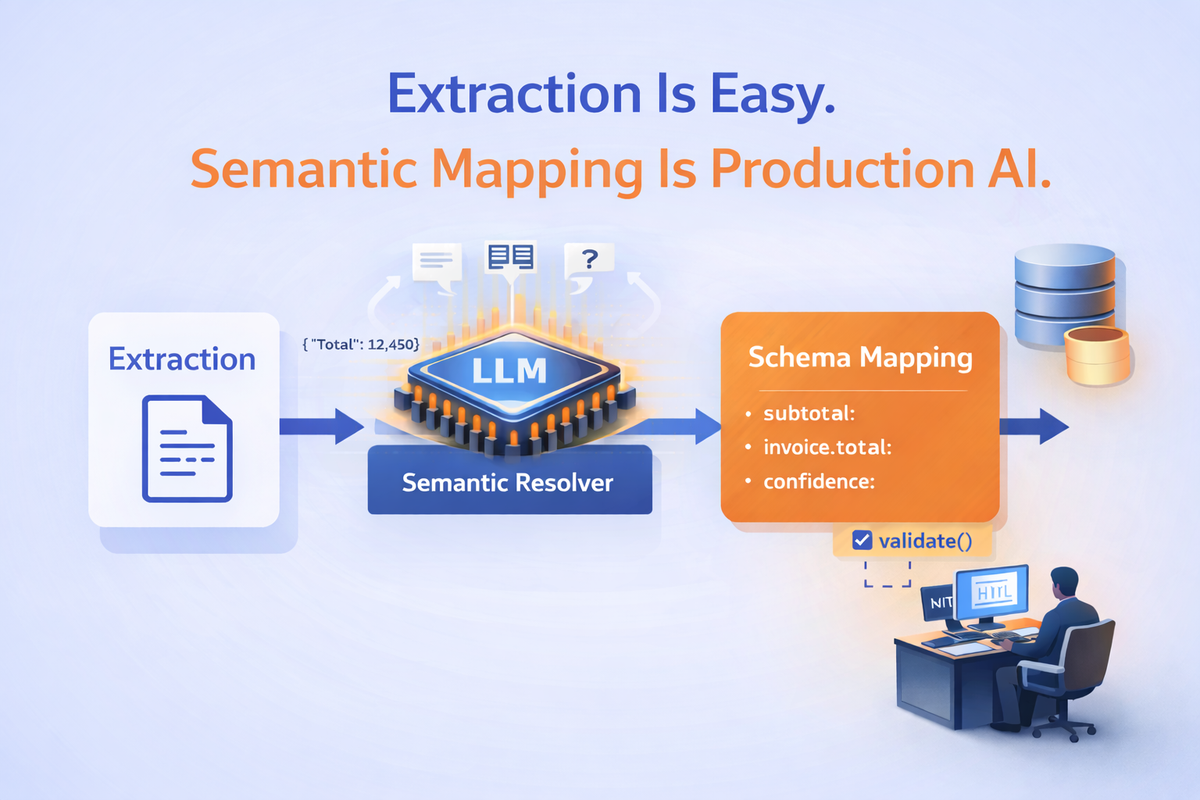
The Semantic Mapping Layer: LLM as a “Resolver”, Not an Extractor
A robust pattern is:
- Extract candidates (keys/values + anchors + table context)
- Resolve them to canonical schema using an LLM
- Validate using deterministic rules + Pydantic types
- Persist only if validation passes (or route to HITL)
The LLM’s job is to answer:
“Given these extracted candidates and their surrounding context, which canonical field does each one map to, and why?”
That “why” becomes critical for audit + HITL.
A Practical Prompt Shape (Resolver Prompt)
The resolver uses your mapping context (ideally stored in a config file and NOT in the prompt) and examples of successful mappings (again ideally stored in a prompt examples config).
Input: extracted candidates + mapping context + your canonical schema registry
Output: canonical field decisions + confidence + evidence
Indicative Resolver Prompt
SYSTEM:
You are a semantic mapping engine for document processing.
Your job is to map extracted fields from a document into a company's canonical schema.
Do NOT invent values. Do NOT change numbers. Only decide the best canonical field for each extracted candidate.
You must:
1) Choose exactly one canonical_field for each extracted candidate, OR mark it as unmapped.
2) Provide a confidence score between 0 and 1.
3) Provide short evidence bullets that explain the decision (based on label, nearby context, and common accounting/document conventions).
4) If two extracted candidates map to the same canonical field, keep the best one and mark the other as unmapped with reason "duplicate_candidate".
OUTPUT MUST BE STRICT JSON matching the provided schema. No extra keys. No prose.
USER:
You are given:
A) Canonical schema registry (fields + descriptions + aka synonyms)
B) Extracted candidates from a document (key, value, and context)
Decide the mapping.
A) CANONICAL_SCHEMA_REGISTRY:
[
{
"field": "financials.revenue_from_operations",
"type": "number",
"description": "Revenue from core operations, excluding other income.",
"aka": ["Revenue from Operations", "Operating Revenue", "Net Sales"]
},
{
"field": "financials.revenue_total",
"type": "number",
"description": "Total income including other income and non-operating income.",
"aka": ["Total Income", "Total Revenue", "Gross Income"]
},
{
"field": "financials.other_income",
"type": "number",
"description": "Non-operating income not part of core operations.",
"aka": ["Other Income", "Non Operating Income", "Misc Income"]
},
{
"field": "financials.ebitda",
"type": "number",
"description": "Earnings before interest, taxes, depreciation and amortization.",
"aka": ["EBITDA", "Operating EBITDA"]
},
{
"field": "financials.ebit",
"type": "number",
"description": "Earnings before interest and taxes. Often called Operating Profit.",
"aka": ["EBIT", "Operating Profit", "Profit Before Interest and Tax"]
},
{
"field": "financials.pat",
"type": "number",
"description": "Profit after tax (net profit).",
"aka": ["PAT", "Net Profit After Tax", "Net Profit", "Profit After Tax"]
}
]
B) EXTRACTED_CANDIDATES:
[
{
"source_key": "Total Income",
"source_value": "1,245,000",
"context": "Statement of Profit and Loss | For the year ended Mar 31, 2023"
},
{
"source_key": "Revenue from Operations",
"source_value": "1,180,000",
"context": "Income"
},
{
"source_key": "Other Income",
"source_value": "65,000",
"context": "Income"
},
{
"source_key": "Operating Profit",
"source_value": "245,000",
"context": "Profit before exceptional items and tax"
},
{
"source_key": "Net Profit After Tax",
"source_value": "182,000",
"context": "Profit for the year"
}
]
Return JSON with this exact schema:
{
"mappings": [
{
"source_key": "string",
"canonical_field": "string",
"confidence": 0.0,
"evidence": ["string"]
}
],
"unmapped": [
{ "source_key": "string", "reason": "string" }
]
}Indicative Output (What the LLM Should Return)
{
"mappings": [
{
"source_key": "Total Income",
"canonical_field": "financials.revenue_total",
"confidence": 0.92,
"evidence": [
"Exact synonym match with canonical aka: 'Total Income'",
"Appears under Income section and represents total income line item"
]
},
{
"source_key": "Revenue from Operations",
"canonical_field": "financials.revenue_from_operations",
"confidence": 0.95,
"evidence": [
"Exact synonym match with canonical aka: 'Revenue from Operations'",
"Common P&L structure: revenue from ops reported separately from other income"
]
},
{
"source_key": "Other Income",
"canonical_field": "financials.other_income",
"confidence": 0.96,
"evidence": [
"Exact synonym match with canonical aka: 'Other Income'",
"Placed under Income section as non-operating income line"
]
},
{
"source_key": "Operating Profit",
"canonical_field": "financials.ebit",
"confidence": 0.78,
"evidence": [
"Canonical aka includes 'Operating Profit' for EBIT",
"Context suggests operating profit before tax/exceptionals, consistent with EBIT"
]
},
{
"source_key": "Net Profit After Tax",
"canonical_field": "financials.pat",
"confidence": 0.97,
"evidence": [
"Exact synonym match with canonical aka: 'Net Profit After Tax'",
"Represents profit for the year after tax (PAT)"
]
}
],
"unmapped": []
}Why does this work?
- Testable: you can score mapping accuracy by comparing
source_key → canonical_field - Auditable:
evidencemakes review and debugging fast - HITL-friendly: low
confidenceor conflicts become clean routing triggers - Regression-ready: prompt changes can be tracked via mapping eval suites
A Harder Case: When the Model Should Hesitate
Not every mapping can be high confidence. In fact, if your resolver always returns >0.9 confidence, that’s a red flag.
Let’s look at an invoice example where ambiguity is real.
Canonical Schema (Invoice)
[
{
"field": "invoice.subtotal",
"type": "number",
"description": "Total before tax and additional charges.",
"aka": ["Subtotal", "Net Amount", "Amount Before Tax"]
},
{
"field": "invoice.tax_amount",
"type": "number",
"description": "Total tax applied to invoice.",
"aka": ["Tax", "GST", "VAT", "Sales Tax"]
},
{
"field": "invoice.total_gross",
"type": "number",
"description": "Final total including tax and charges.",
"aka": ["Grand Total", "Total Amount", "Invoice Total", "Amount Payable"]
}
]Extracted Candidates (Ambiguous Case)
[
{
"source_key": "Total",
"source_value": "12,450.00",
"context": "Appears at bottom right of invoice"
},
{
"source_key": "Amount Payable",
"source_value": "12,450.00",
"context": "Below Total"
},
{
"source_key": "Tax",
"source_value": "1,245.00",
"context": "GST 12%"
}
]Now we have ambiguity:
- “Total” might be subtotal or gross
- “Amount Payable” might already include tax
- Both have identical values
This is where a weak resolver could confidently hallucinate. You need to build the ability for your resolver to hesitate.
Expected Resolver Output (With Ambiguity Reflected)
{
"mappings": [
{
"source_key": "Amount Payable",
"canonical_field": "invoice.total_gross",
"confidence": 0.74,
"evidence": [
"Common synonym for final invoice amount",
"Appears as bottom-most payable figure",
"Value consistent with tax + subtotal pattern"
]
},
{
"source_key": "Tax",
"canonical_field": "invoice.tax_amount",
"confidence": 0.96,
"evidence": [
"Exact synonym match",
"Context explicitly mentions GST 12%"
]
}
],
"unmapped": [
{
"source_key": "Total",
"reason": "Ambiguous between invoice.subtotal and invoice.total_gross"
}
]
}Notice what happened:
- The model did not map both “Total” and “Amount Payable” to
invoice.total_gross - It selected one with moderate confidence
- It explicitly marked the other as ambiguous
- It surfaced reasoning for audit
This is a good outcome since overconfident mapping would have been more dangerous than partial mapping.
How This Connects to HITL
Your routing logic becomes clean and deterministic:
def should_route_to_hitl(mapping_result, validation_errors):
low_conf = any(m["confidence"] < 0.80 for m in mapping_result["mappings"])
has_unmapped = len(mapping_result.get("unmapped", [])) > 0
return low_conf or has_unmapped or len(validation_errors) > 0In this case:
- confidence = 0.74 → below threshold
- 1 unmapped field → trigger
Only the ambiguous fields go to review.
The reviewer sees:
- extracted candidates
- canonical options
- model’s reasoning
- conflicting labels
They do not have to review the entire PDF.
Implementation Pattern
Here's a production-grade implementation separates responsibilities cleanly:
1. Canonical Schema Registry
Your internal schema must be explicit and versioned.
Not just Pydantic models — but metadata:
- Field name
- Type
- Description
- Synonyms (aka)
- Unit expectations
- Validation dependencies
This registry is what the resolver sees and this is the source of truth.
2. Extraction Layer (Model Output)
Extraction should return:
- Structured candidates (key, value)
- Nearby textual context
- Table anchors (if relevant)
- Extraction confidence
Do not mix semantic decisions here.
3. Semantic Resolver (LLM-Based Mapping)
The resolver:
- Receives extracted candidates + canonical registry
- Selects canonical fields
- Outputs confidence + evidence
- Explicitly marks ambiguous or unmapped cases
It produces a decision artifact, not a final record.
That artifact is:
- Logged
- Evaluated
- Audited
- Used for HITL routing
4. Deterministic Normalization + Validation
After mapping:
- Normalize numbers (units, scaling, currency)
- Enforce type constraints
- Apply cross-field business rules
- Detect conflicts or impossible states
While the LLMs decide meaning, good old code enforces correctness.
5. HITL as a Targeted Override
Route only when:
- confidence < threshold
- unmapped fields exist
- validation fails
Humans become more efficient reviewing mapping decisions, not entire documents.
Corrections are stored as:
- New labeled eval samples
- Regression test cases
What You Should Actually Evaluate
This is where most teams under-invest.
They evaluate extraction (“did we get the number”), but mapping is what breaks workflows.
You need evals at three layers:
1. Field-level semantic mapping accuracy
Did the resolver map to the correct canonical field?
- expected:
financials.revenue_total - predicted:
financials.revenue_from_operations - that’s a failure even if the value is correct
2. End-to-end schema correctness
After mapping + normalization + validation, does the final object match expected?
3. Downstream acceptance
Did the ERP/DB accept the record without manual edits?
The Evals Question (What you must do at a minimum)
There are three things you need to measure:
- Field-level semantic mapping accuracy
- Confidence calibration
- Regression stability across prompt versions
You are testing whether:
Given the same extracted candidates and canonical schema,
does the resolver choose the correct canonical fields?
1. Build a Labeled Mapping Dataset
At minimum, you need:
- A set of representative documents
- Their extracted candidates (post-extraction output)
- Expected canonical mappings
- Expected unmapped cases
Each test case should look like this:
{
"test_id": "pnl_v1_basic",
"doc_type": "pnl_statement",
"extracted_candidates": [
{"source_key": "Total Income", "source_value": "1245000"},
{"source_key": "Revenue from Operations", "source_value": "1180000"},
{"source_key": "Other Income", "source_value": "65000"}
],
"expected_mappings": {
"Total Income": "financials.revenue_total",
"Revenue from Operations": "financials.revenue_from_operations",
"Other Income": "financials.other_income"
},
"expected_unmapped": []
}Important:
- Store this as JSON in your repo.
- Version control it.
- Treat it like unit tests.
2. Include Hard and Ambiguous Cases
Your evals dataset has to be a mix of
- Clean cases: Exact synonym matches.
- Near-synonym cases: "Operating Profit” →
financials.ebit - Ambiguous cases: “Total” vs “Amount Payable”
- Conflict cases: Two candidates competing for one canonical field.
- Schema-miss cases: Fields that should be unmapped.
Your eval dataset should represent the actual mess of production.
3. Scoring: Field-Level Mapping Accuracy
You’re not checking numbers. You’re checking decisions.
Example scoring logic:
def mapping_accuracy(expected, predicted_mappings):
predicted = {
m["source_key"]: m["canonical_field"]
for m in predicted_mappings
}
correct = 0
total = len(expected)
for source_key, expected_field in expected.items():
if predicted.get(source_key) == expected_field:
correct += 1
return correct / totalTrack:
- Overall mapping accuracy
- Accuracy per doc type
- Accuracy per canonical field
If one canonical field consistently fails, that’s a signal.
4. Test Confidence Calibration
Your resolver outputs confidence. Now test whether it behaves rationally.
Questions to ask:
- Are high-confidence predictions actually correct?
- Do incorrect predictions cluster at lower confidence?
- Are ambiguous cases producing lower confidence?
At minimum, log:
- confidence distribution for correct predictions
- confidence distribution for incorrect predictions
If incorrect predictions frequently have confidence > 0.9, your resolver is overconfident and your HITL thresholds are meaningless.
5. Track Unmapped Behavior
Unmapped cases are important.
You should measure:
- % expected unmapped correctly left unmapped
- % incorrect over-mappings (forced mapping when it shouldn’t)
Over-mapping is more dangerous than under-mapping. If the model aggressively assigns canonical fields when it shouldn’t, your downstream system will degrade silently.
The Real Boundary in Document AI
If you zoom out, the evolution looks like this:
- pre-2022: Can we extract text reliably?
- 2022-2024: Can we structure it?
- 2024-2025: Can we validate it?
- 2025-2026: Can we safely drive workflows with it?
That last question is where semantic mapping lives.
Extraction gives you data, Validation tells you whether the data is self-consistent. Semantic mapping determines whether the data is meaningful inside your system.
That is the real boundary: the point where probabilistic model output becomes deterministic enterprise state.
If you want to hear about real implementation patterns of semantic mapping, talk to us today.
Book your complementary session
Frequently Asked Questions
1. What is “semantic mapping” in document AI?
Semantic mapping is the step where extracted fields (labels + values + context) are mapped to an organization’s canonical internal schema. It answers “what does this extracted field mean in our system?”—for example mapping “Total Income” to financials.revenue_total or “Amount Payable” to invoice.total_gross.
2. How is semantic mapping different from data extraction?
Extraction pulls text, tables, and key-value pairs from documents. Semantic mapping resolves ambiguity and normalizes the output into the internal fields your ERP, database, or analytics schema expects. A system can have “accurate extraction” and still fail in production if mapping is wrong or inconsistent.
3. Why does schema mapping break in production?
Schema mapping breaks because vendor templates vary, labels collide (“Total”, “Net Amount”, “Grand Total”), units are implicit (thousands/millions), and internal schemas evolve over time. The same phrase can map to different canonical fields depending on document type, layout, surrounding context, and business rules.
4. Can an LLM be used for semantic mapping to internal schemas?
Yes—LLMs are well-suited as a semantic “resolver” that chooses the best canonical field for each extracted candidate based on context and schema definitions. In production, the LLM should output a structured decision artifact: source_key → canonical_field with confidence and evidence, plus explicit unmapped cases for ambiguity.
5. What should a canonical schema registry include?
A canonical schema registry should include field name, data type, description, unit expectations, and synonyms/aliases (“aka”). For example: financials.revenue_from_operations with synonyms like “Net Sales” and “Operating Revenue”. This registry is the source of truth your semantic resolver uses to map extracted fields reliably.
6. What is the minimum eval setup for semantic mapping?
At minimum, maintain a version-controlled JSON test suite with (a) extracted candidates (the resolver input) and (b) expected canonical mappings (the ground truth output), including ambiguous cases that should be left unmapped. Run this suite on every prompt change, schema change, or model change to catch regressions early.
7. How do you evaluate semantic mapping accuracy?
Evaluate mapping at the decision level, not the number level. The core metric is: did the resolver map each source_key to the correct canonical_field? Track accuracy overall, by document type (invoices vs financial statements), and by canonical field (which fields are consistently confused).
8. What are common semantic mapping gotchas for invoices?
Invoices often contain ambiguous totals (“Total” vs “Amount Payable”), inconsistent tax representations (GST/VAT/cess/withholding), and line items that mix products, discounts, and taxes. Robust mapping typically requires confidence thresholds, duplication handling, and deterministic validation checks like subtotal + tax = total (with tolerances).
9. What are common semantic mapping gotchas for financial statements?
Financial statements have semantic collisions like “Total Income” vs “Revenue from Operations” vs “Other Income”, and metric variants like “Operating Profit” (EBIT vs EBITDA depending on context). Mapping requires schema-aware resolution, evidence logging, and cross-field validation (e.g., total income should reconcile with revenue + other income where applicable).
10. What is “over-mapping” and why is it dangerous?
Over-mapping is when the resolver forces a canonical field assignment even when the correct action is “unknown/ambiguous”. Over-mapping is more dangerous than under-mapping because it creates silent downstream corruption (wrong field populated) that may pass basic validations and only show up later in reporting or audits.
11. How do you introduce Human-in-the-Loop (HITL) for semantic mapping?
HITL should be field-level and triggered by low confidence, conflicting candidates, unmapped fields, or validation failures. Reviewers should see the decision artifact (candidate, chosen canonical field, evidence, and alternatives) rather than the entire document. Corrections should be logged and added back to the mapping eval suite as new labeled test cases.
12. How do you prevent regressions when prompts or schemas change?
Version your resolver prompt and canonical schema registry, and run mapping regression tests on every change. Store per-version results and compare them (e.g., accuracy by doc type, over-mapping rate, confidence distribution). Treat prompt updates like code changes: they must pass tests before they ship.