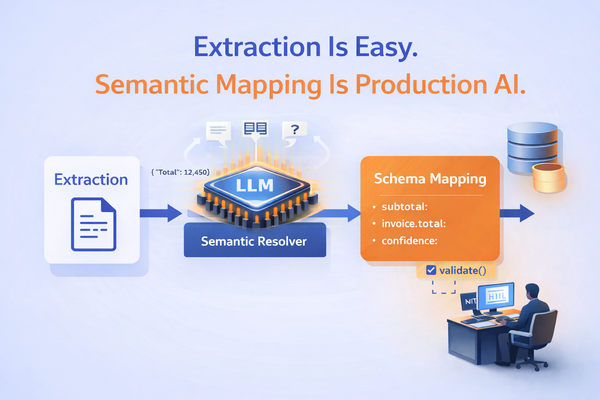
Document Processing isn't just Extraction
Document processing isn’t just LLMs and OCR. Learn how validation, normalization, and workflows make AI production-ready.

For the last few years, document processing in AI has largely meant document extraction.
How accurately can you pull text, tables, and key-value pairs from PDFs, scans, and images?
This focus made sense when extraction itself was the hard problem.
But in 2026, the bar has shifted.
With strong open-source models, multimodal LLMs, and maturing OCR pipelines, basic extraction is no longer a differentiator. Tools like LlamaParse, Reducto, Mistal OCR and several cloud-native OCR systems can get you some output, most of the time.
The real question enterprises now ask is simpler, but much harder:
So how can I drive my workflows with the data I have “extracted”?
That’s where document processing truly begins.
The Hidden Gap in Most Document AI Solutions
Most document AI stacks stop at a familiar milestone:
- Text extracted
- Tables detected
- JSON output generated
But for developers, this is where the real work starts.
- Is this extraction accurate enough for our downstream modules?
- Does this match our internal schema or do I need additional normalization?
- Can this be validated against our internal rules?
- What happens when documents change shape?
- Can it flow directly into our existing systems?
- How do we re-run or audit this pipeline six months later?
Extraction without context is just structured noise.
Why Extraction Accuracy Alone Is Not Enough
Even with high-quality extractors, enterprises face three persistent issues:
1. Accuracy Is Contextual, Not Absolute
A 98% extraction accuracy means nothing if:
- The missing 2% contains critical fields
- Tables are parsed correctly but semantically misinterpreted
- Footnotes override primary values
From a system design perspective, accuracy must be evaluated relative to how the data is used, not against generic benchmarks.
2. Raw Outputs Rarely Match Business Formats
Most extractors return:
- Flat key-value or semi-structured JSON or Markdown
- Inconsistent field naming
- Tables without semantic meaning
Real systems require:
- Canonical schemas
- Normalized units, currencies and dates
- Fiscal year and domain specific logic
- Derived fields and calculations
- Explicit handling of missing or ambiguous values
This normalization layer is where most document pipelines quietly accumulate complexity.
3. Non-Determinism Leaks Downstream
Developers quickly discover that:
- Small extraction changes break validations
- Prompt updates subtly change summaries
- Edge cases are hard to replay or debug
Without clear stage boundaries and validation contracts, pipelines become non-reproducible and difficult to reason about.
4. Humans Don’t Read JSON. They Read Narratives
Decision-makers don’t want:
"interest_rate": 13.75
They want:
“The borrower’s interest rate increased by 125 bps compared to the previous loan, driven by higher risk classification.”
Summaries, narratives, and insights are not optional. They are the final product.
Document Processing as a Pipeline, Not an API Call
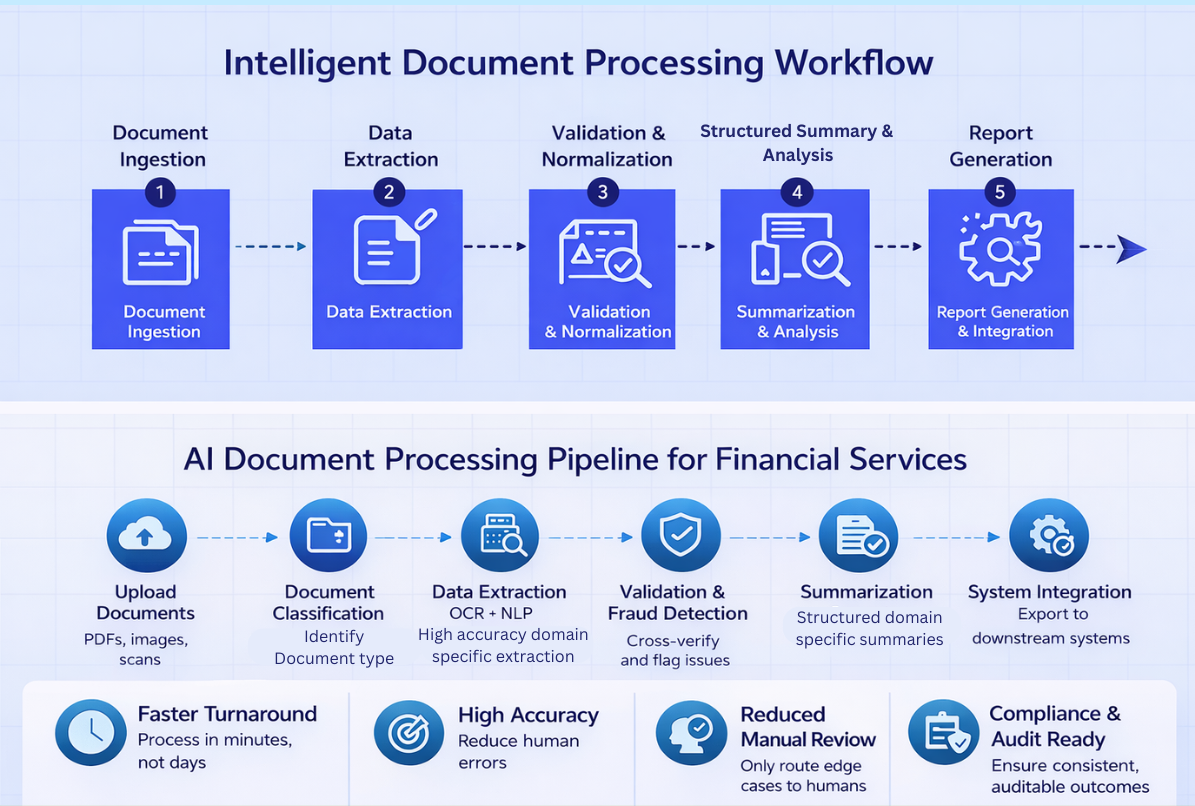
Modern document processing should be thought of as a versioned, replayable pipeline, not a one-shot inference call.
A robust system typically looks like this:
1. Extraction
Use best-in-class OCR and parsing models for text, tables, and layouts. This stage should focus on fidelity, not business logic.
2. Validation
Explicit checks such as:
- Are required documents present?
- Do totals reconcile?
- Are date ranges valid?
- Do values agree across documents?
This is where probabilistic outputs meet deterministic rules.
3. Normalization
Map extracted data into business-defined schemas:
- Canonical field names
- Unit and currency normalization
- Domain logic (FY vs CY, thresholds, rounding)
For developers, this stage is critical. It’s what makes downstream systems stable.
4. Summarization & Insight Generation
Transform structured data into:
- Analyst-readable summaries
- Exception reports
- Decision-ready narratives
Humans don’t read JSON. Systems must bridge that gap reliably.
5. Integration & Outputs
Finally:
- Generate reports
- Push clean data into downstream systems
- Maintain traceability from source document → extracted value → final decision
This is where auditability matters.
Loan Processing: A Canonical Failure Case for Point Solutions
Loan processing exposes the limits of extraction-only approaches very quickly.
A typical loan file includes:
- Financial Statements (for companies)
- Bank statements
- Income proofs
- Tax documents
- Credit reports
- Application forms
Extraction alone gives you fragments.
A production-grade system must:
- Verify document completeness
- Normalize transactions across banks and financial statements
- Detect anomalies and inconsistencies
- Summarize cash flow stability
- Generate analyst-ready credit notes
This is not a parsing problem.
It’s a workflow orchestration problem.
Why End-to-End Systems Win in an AI-First World
AI has dramatically lowered the cost of building point solutions.
Which paradoxically makes integration, orchestration, and reliability the real moat.
End-to-end systems win because they:
- Reduce human-in-the-loop overhead
- Eliminate brittle post-processing code
- Limit non-determinism leaking downstream
- Deliver outcomes, not intermediate artifacts
In regulated domains, partial automation often increases risk rather than reducing it.
Where Agami Fits In
At Agami AI, we don’t try to reinvent extraction.
We deliberately:
- Leverage state-of-the-art document extractors
- Extend them with AI-driven validation, normalization, and summarization
- Setup audit trails of every AI decision made to enable HITL where critical
- Build end-to-end, versioned workflows that engineers can reason about
- Create large volumes Synthetic data from limited real production data.
- Setup AI Evals that test every step in the workflow
Our focus is simple:
Treat document processing as a workflow towards achieving a business use case.
Because the value isn’t in reading documents faster, it’s in driving better outcomes because of them .
The Future of Document Processing
As AI becomes ubiquitous, document processing will no longer be a standalone category.
As AI becomes ubiquitous, document processing will no longer be judged by:
- OCR accuracy
- Model benchmarks
- Demo performance
It will be judged by:
- Time-to-decision
- Failure rates in production
- Auditability and traceability
- Developer trust in the system
Extraction will be assumed.
Everything that comes after will define the winners.
If you’re building or evaluating document AI systems and want to move beyond extraction demos into real workflows, talk to us today.
Book your complementary session
Frequently Asked Questions
1. What is Intelligent Document Processing (IDP)?
Intelligent Document Processing (IDP) refers to end-to-end systems that ingest documents, extract data, validate and normalize it, generate summaries or insights, and integrate results into downstream systems. Unlike basic OCR or extraction tools, IDP focuses on production-ready workflows rather than standalone outputs.
2. How is document processing different from OCR or document extraction?
OCR and document extraction focus on converting documents into text or structured data. Document processing goes further by adding validation, normalization into business schemas, summarization, anomaly detection, and system integration. Extraction is only one stage in a larger decision pipeline.
3. Why do document extraction pipelines often fail in production?
Most extraction pipelines fail because downstream logic becomes brittle. Common issues include schema drift, non-deterministic LLM outputs, lack of validation contracts, poor replayability, and difficulty auditing why a value was produced. These failures surface only at scale, not during demos.
4. What are the biggest challenges developers face when building document AI systems?
Developers typically struggle with inconsistent document formats, normalization across vendors or banks, validation logic scattered across codebases, handling edge cases, reprocessing historical documents, and maintaining reproducibility when models or prompts change.
5. Why is validation and normalization critical in document processing?
Validation ensures extracted data is internally consistent and usable, while normalization maps outputs into canonical business schemas. Without these steps, downstream systems become unstable, analytics break, and small extraction changes cascade into production failures.
6. How does AI-powered document processing work in loan processing?
In lending workflows, AI-powered document processing verifies document completeness, extracts financial data, normalizes transactions across banks, detects anomalies, summarizes cash-flow stability, and generates analyst-ready reports. This enables faster, more consistent credit decisions compared to manual review.
7. Are end-to-end document processing systems better than point solutions?
Yes. End-to-end systems reduce brittle glue code, limit non-determinism leaking downstream, improve auditability, and deliver business outcomes instead of intermediate artifacts. As extraction becomes commoditized, orchestration and reliability become the primary differentiators.
8. How should teams evaluate document AI solutions before production?
Teams should evaluate solutions on replayability, schema stability, validation coverage, auditability, handling of edge cases, and ease of integration into existing systems. OCR accuracy alone is not a reliable indicator of production readiness.
9. Can document processing pipelines be made deterministic?
While some stages remain probabilistic, pipelines can be made predictable by enforcing validation contracts, separating deterministic and probabilistic stages, versioning prompts and schemas, and enabling reprocessing and audits. This is essential for regulated industries.
10. What should developers prioritize when designing document processing workflows?
Developers should prioritize clear pipeline stages, canonical schemas, validation rules, replayability, and traceability from source documents to final outputs. Designing for failure and iteration is more important than optimizing for extraction accuracy alone.