Buy a CRM Subscription. Own Your Data Agent.
AI is killing SaaS, but the data agent is the one piece you should own. Here is the architecture OpenAI, Meta, and Notion converged on, and three ways to ship yours.
AI is supposedly killing SaaS. CRM will survive but the data agent is the one you'll regret renting.
OpenAI, Meta, and Notion all just shipped their own. Here's how to own one without their headcount.
TL;DR
- Two engineers at OpenAI built a data agent in three months, now used by ~4,000 of the company's employees daily; OpenAI's own write-up describes the architecture: GPT-5.2 reasoning over ~70,000 datasets and 600+ petabytes via six layers of context.
- Meta's home-grown version reached 77% weekly adoption inside its data team within six months, plus ~5x as many non-data users. Notion built one too.
- The key patterns underneath these agents are similar: a semantic / knowledge layer, reasoning over context, retrieval, memory, and a continuous evaluation loop. At Agami, we've spent two years shipping the same architecture for enterprises and we're now open-sourcing the components, one post and one open-source skill at a time.
Two engineers. Four thousand daily users.
Per VentureBeat's reporting: two engineers, three months, ~70% of the code AI-written, now serving ~4,000 of the company's employees with an internal estimate of 2 to 4 hours of work saved per query. OpenAI's own write-up fills in the architecture: GPT-5.2 reasoning over ~70,000 datasets and 600+ petabytes via six layers of context, embedded into Slack, internal web, IDEs, the Codex CLI, and ChatGPT.
You probably shouldn't build your own CRM. Salesforce solved that twenty years ago. Lead, opportunity, account, contact, stage. Those are workflows the world has agreed on, and most companies operate inside them comfortably.
But you should own your data agent. And "own" doesn't mean "build from scratch." That's one valid path. There are two others, both better suited to most companies.
Here's why ownership is the question, and the three paths to land on an answer.
The build-or-buy test
The test
Before writing a line of code, ask: does the value of this software depend on workflows the world has standardized, or on workflows unique to your business?
Why CRM falls on the standardized side
The reasons most companies don't build a custom CRM are well-rehearsed: the sales process is commoditized (lead → opportunity → close), security and compliance work is solved, integrations to email/calendar/billing already exist, and the maintenance cost of a homegrown system is brutal. Salesforce isn't loved because it's the perfect tool; it's adopted because the workflows it encodes are the workflows everyone agreed on. Building your own would mostly mean rebuilding common knowledge, badly.
Why a data agent falls on the unique side
A data agent is the inverse on every axis.
The workflows aren't commoditized. What's our P1 incident SLA breach rate by assignment group? and which accounts churn within 90 days of their first support escalation? aren't questions every company asks the same way. They depend on your tables, your metric definitions, your business logic, your edge cases. The semantic layer the agent needs is the same artifact that defines your company's metrics. No vendor can ship that pre-baked. Anyone who tries has just re-shaped your business around their categories.
The hard, expensive part of building a data agent has also just been commoditized, but in a different direction. Frontier LLMs (Claude, GPT, Gemini) now do the reasoning that two years ago required armies of ML engineers. What's left to build is the context layer around them: the semantic model, the memory, the evaluation loop, the integrations to your stack. That part is uniquely yours, and it's the part that compounds.
What a data agent unlocks
Most importantly, your data agent isn't just a query tool. It's the substrate for everything you'll automate with AI next:
- The weekly business review that runs itself every Monday at 7am and lands in the leadership Slack channel as a five-bullet summary.
- The alerts and root-cause loops that notice when revenue drops on Tuesday and walk back the chain of deploys, signups, and downstream queries to find the cause, the way Meta's agent does.
- The shift from ticket queue to self-serve that data teams have been chasing for a decade.
- The integrations into your internal knowledge sources (your wiki, your design docs, your code) so a question about feature performance can pull the launch timestamps directly from the deploy log instead of waiting on someone to remember.
- The custom tools you wire up that other agents call (a finance agent, a support agent, a marketing agent), each pulling validated numbers from the same data layer.
You build that around your data, your definitions, your processes. You don't rent it.
The test: do the workflows depend on what the world has standardized, or on what's unique to your business? CRM workflows? Standardized: buy. Data-agent workflows? Yours: build.
What an AI data agent actually is, and how it differs from 2023's text-to-SQL
The phrase "AI data agent" gets used loosely. A working definition, drawn from how OpenAI, Meta, ThoughtSpot, Databricks, and Cube describe these systems in the agentic-semantic-layer framing:
An AI data agent turns natural-language business questions into validated, policy-aware answers from your data: reasoning over a semantic model of your business, planning multi-step queries, executing them, validating the results, and learning from feedback over time.
You've seen the older version of this. Three years ago, "natural language to SQL" demos were everywhere. They worked great in a five-minute demo and fell apart on real enterprise data. The typical pattern was a single LLM call, schema-only grounding, no evaluation, no improvement loop. They hallucinated table names. They joined data incorrectly. They broke the moment your schema changed.
The 2026 version is structurally different in five ways.
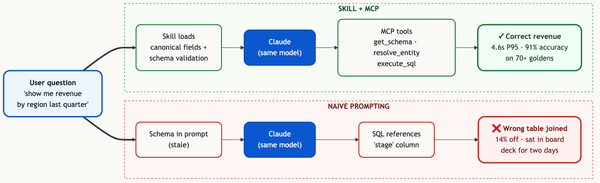
1. Reasoning agents instead of single-shot. A single LLM call can't reliably classify a question, resolve the entities, plan a multi-table join, generate SQL, validate it, and format the result. Several specialized agents working in sequence can. Same model, different behavior.
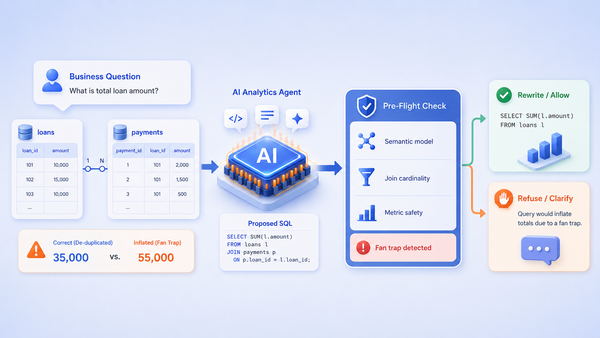
2. Semantic-layer-grounded. Schema alone tells the agent there's a subscriptions table with an amount column. The semantic model tells it that at your company, ARR is a measure: the sum of monthly recurring values from active subscriptions multiplied by 12, with filters on subscription status and line-item type to exclude one-time fees and pending cancellations. The same definition your finance team aligned on last quarter, applied everywhere. Without this layer, "what's our ARR?" is a coin flip.
3. Deterministic where it matters. "Show me Acme Corp's tickets" has exactly one right answer when "Acme" is unambiguous. The hard cases (multiple customers named "Acme," misspellings, abbreviations, partial matches) are where most pure-LLM approaches quietly fall apart, and where production-grade entity resolution earns its keep. (More on the index that makes this work under Entity search index below.)
4. Self-measuring. Two things drift in production, and they need different instruments. Regression (the same question silently starts returning a worse answer as the model or schema changes) is caught by running a curated golden dataset daily as a regression test. Coverage (new questions appear that nobody anticipated) is caught by sampling real production traffic with auto-grader feedback. A serious data agent does both.
5. Self-healing. When it gets something wrong, the corrected SQL is captured as a learned correction: a structured few-shot retrieved by question-intent similarity at the next query. The next time a similar question comes up, that correction is surfaced as authoritative context, and the same mistake is materially less likely to repeat. The mechanism is prompt-level retrieval, not gradient updates: no fine-tuning, no code deploy, just a thicker context layer that compounds.
That last pair is what most teams underestimate. As Notion's data team has put it bluntly:
"Write a metadata description for each row, for each column, and for each table that you have, so AI knows what it is looking at when it queries it. Otherwise it is going to produce a bunch of BS, and you would never know if it is true or not."
Context is the hard part, and it gets harder every quarter.
The proof: OpenAI, Meta, Notion, and Agami all built their own
You don't have to take this on faith. In the last six months, three of the most data-mature companies in the world have written publicly about their internal data agents. We've spent the last two years shipping the same architecture for enterprises. All four converged on the same shape.
OpenAI
OpenAI's Inside our in-house data agent describes a GPT-5.2-powered system that grounds the LLM in six explicit layers of context: (1) table usage: schema and lineage plus inference from historical queries (which tables do analysts actually join for this kind of question?); (2) human annotations: curated descriptions from domain experts; (3) Codex enrichment: Codex reads pipeline code and extracts semantic meaning at the source; (4) institutional knowledge: Slack, Notion, and Google Docs with permissions intact; (5) memory: past corrections and learned filters; (6) runtime context: live queries when prior context is stale. A daily offline pipeline aggregates the first three layers into embeddings retrieved at query time via RAG.
Meta
Inside Meta's Home Grown AI Analytics Agent (March 30, 2026) opens with the stat that makes this category tractable:
"88% of queries by Data Scientists rely solely on tables queried in the preceding 90 days."
Most data work is repetitive.
Notion
Notion's data team built an internal Snowflake-connected agent that other Notion agents (an "AI Transformer," for instance) call into for the data layer: "a data scientist on call," in their words. Their lesson echoes Meta's: metadata at the row, column, and table level is non-negotiable, or the agent produces confident BS nobody notices.
Agami
The fourth example: us. We've spent two years deploying this architecture for enterprises: portable YAML semantic model, reasoning agents, deterministic entity resolution, continuous evaluation with learned corrections. Our team came from data platform engineering at Google, Meta, and Yahoo.
The detail that matters: in Agami, the customer owns the semantic model, the prompt examples, and the golden datasets. Files in your git repo. Walk away and you keep them, working against any LLM and any warehouse.
Same architecture as the big-tech in-house agents. None of the lock-in.
The real question: whose asset is the intelligence?
Notice what those four teams have in common. Each made sure the things that compound (the semantic model, the memory, the evals, the learned corrections) belong to them. That's the strategic point.
A data agent gets smarter every quarter. Each correction tightens a metric definition; each eval failure produces a training example; each clarification thickens the memory. After a year of production use, the agent isn't the model the vendor shipped. It's that model plus a thousand small adjustments that encode how your business actually thinks. That accumulated layer is the asset. Whose asset is it? Three paths, distinguished by where the intelligence accrues:
- Build from scratch. It accrues to you. The OpenAI / Meta / Notion path. Viable if you have a senior platform team and months to spare.
- Adopt a BI-vendor agent. It accrues to the vendor. Every correction teaches their tool, not yours. The next section is why this is the worst of the three.
- Adopt a portable platform. It accrues to you, while someone else writes the code. Use a partner whose semantic model, evals, and memory live in your git, runnable on your infra (or as a managed service if you prefer). You skip the build and keep the artifacts. That's Agami's bet.
Pick where the intelligence compounds for you.
Why not the BI-vendor agent (the new lock-in)
There's a tempting alternative right now. The BI vendors are pitching:
"You don't have to build it. We already did. Just turn it on."
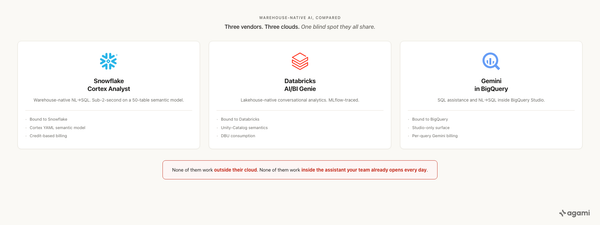
Snowflake Cortex Analyst. Databricks Genie. Tableau + Waii. Power BI Copilot.
These are worse traps than the old SaaS lock-in. Five reasons.
1. Single-warehouse gravity. A warehouse-bolted agent can only reason fluently about what's in the vendor's universe. Real enterprises have ServiceNow, Salesforce, ad platforms, billing, product analytics, across different vendors. (Yes, connectors exist: Snowflake has external tables, Databricks Genie sits on Unity Catalog federation, Power BI ships 150+ connectors. But the agent's reasoning is still anchored to the home warehouse's metadata model. Federation lets it read; it doesn't make it fluent.) Asking a Snowflake-bolted agent a serious cross-system question still pushes you toward ETLing everything into Snowflake first. Your data agent strategy quietly becomes a data migration program.
2. The meter sits on the vendor's profit margin. The LLM costs money in any architecture, including ours. The problem with per-query/per-token vendor pricing is that the meter is the vendor's meter, marked up over the model price with no visibility into the multiple. Several are free today; that's the introductory rate, not the steady state. Owning the LLM contract directly puts the meter on the model provider's economics, where your finance team can negotiate it like any other infra contract.
3. No portable semantic model (yet). The metric definitions you encode today live inside each vendor's proprietary format. Switch BI vendors, and you redo the model. Compare to a portable YAML you keep in git. To their credit, the warehouses know this can't last. Snowflake, Databricks, dbt Labs, Salesforce, BlackRock, JPMC, and 40+ others are now backing the Open Semantic Interchange (OSI), the vendor-neutral specification for exchanging semantic metadata (announced September 23, 2025; spec finalized). The honest read: the standard exists; the in-product implementations lag.
4. Your accumulated intelligence stays with the vendor. A good agent has memory: corrections you've made, metric definitions you've refined, entity defaults you've taught it, the date conventions your team uses. Each correction makes the next answer smarter. With a BI-vendor agent, that memory lives in their system, not yours. You're paying to teach their tool. Switch vendors, and the intelligence stays behind. The agent gets a year smarter every year you use it. Whose asset is that, yours or theirs?
5. The agent is not yours. When the vendor ships a new version, your prompts, your few-shots, your golden questions, none of it travels. You don't even know what changed.
Then there's the structural problem. None of the in-house agents at OpenAI, Meta, or Notion live inside a BI tool. They live on the LLM, with a portable semantic layer pointing at whatever data systems exist. That isn't an accident. An LLM-native agent is separable from any one vendor. Swap LLMs as the frontier moves. Swap warehouses as you migrate. The semantic model and the golden datasets and the memory travel with you. The BI-vendor agent locks all three together.
For most enterprises, the data agent is on track to become one of the small number of AI tools the company can't function without. That's not a partnership. That's a dependency. Pick the dependency carefully.
The components (and how the open-source skills relate to them)
Context is the hard part. Every component below is, ultimately, a way of producing or preserving context. Here's what's inside Agami's data agent. (If you'd rather try the pieces yourself, the open-source skills start landing alongside the next post in this series. Keep reading or skip to What's coming next.)
A note on what we open-source, and why.
The OpenAI / Meta / Notion posts are inspiring, but their codebases stay inside their walls. The teams who most need this architecture (the 500-to-5,000-person enterprises whose data leaders read those posts and think "that's exactly what we need") are left with diagrams and no code. Our open-source skills are an attempt to close that gap. Skills are an open format (markdown + YAML frontmatter) supported across Claude, ChatGPT, Cursor, Codex, and other agent runtimes; the artifacts they manage (semantic model, evals, memory) are LLM-agnostic by design. They are runnable workflows that put the same architecture into practice for individual tasks: generating a semantic model from your warehouse, querying your data in natural language, evaluating that model against golden questions. Each skill leans on several components at once. They run locally, are free, and don't require any Agami infrastructure. Take them. Build on them. If possible, improve them.
What we ship as a product is the production deployment of the same architecture, in three shapes depending on how you want to operate it:
| Shape | Deployed by | Operated by | Where it runs | Best fit |
|---|---|---|---|---|
| Self-deployable harness | You | You | Your cloud / your infra | Platform engineering, full runtime control |
| Managed SaaS | Agami | Agami | Agami-hosted | Fastest time-to-value, minimal ops |
| On-prem install | Agami | You | Inside your security boundary | Regulated, data-residency, on-prem-first IT |
Notice the middle column. Across all three shapes, the durable artifacts (semantic model, evals, memory, golden datasets) live in your git and travel with you. What changes is who operates the runtime, not who owns the IP. That's intentional: ownership of the compounding artifacts is the whole point.
All three are the assembled thing, operated continuously. They add the pieces a single skill session can't carry on its own: persistent memory across sessions and users, the entity search index, evals running on a schedule, authentication and access controls, and the ongoing accuracy support that keeps the agent working as your data drifts.
The series below pairs each architectural deep-dive with the open-source skill that brings it to life, where one is shipping. The enterprise-only components get a deep-dive without an open-source release.
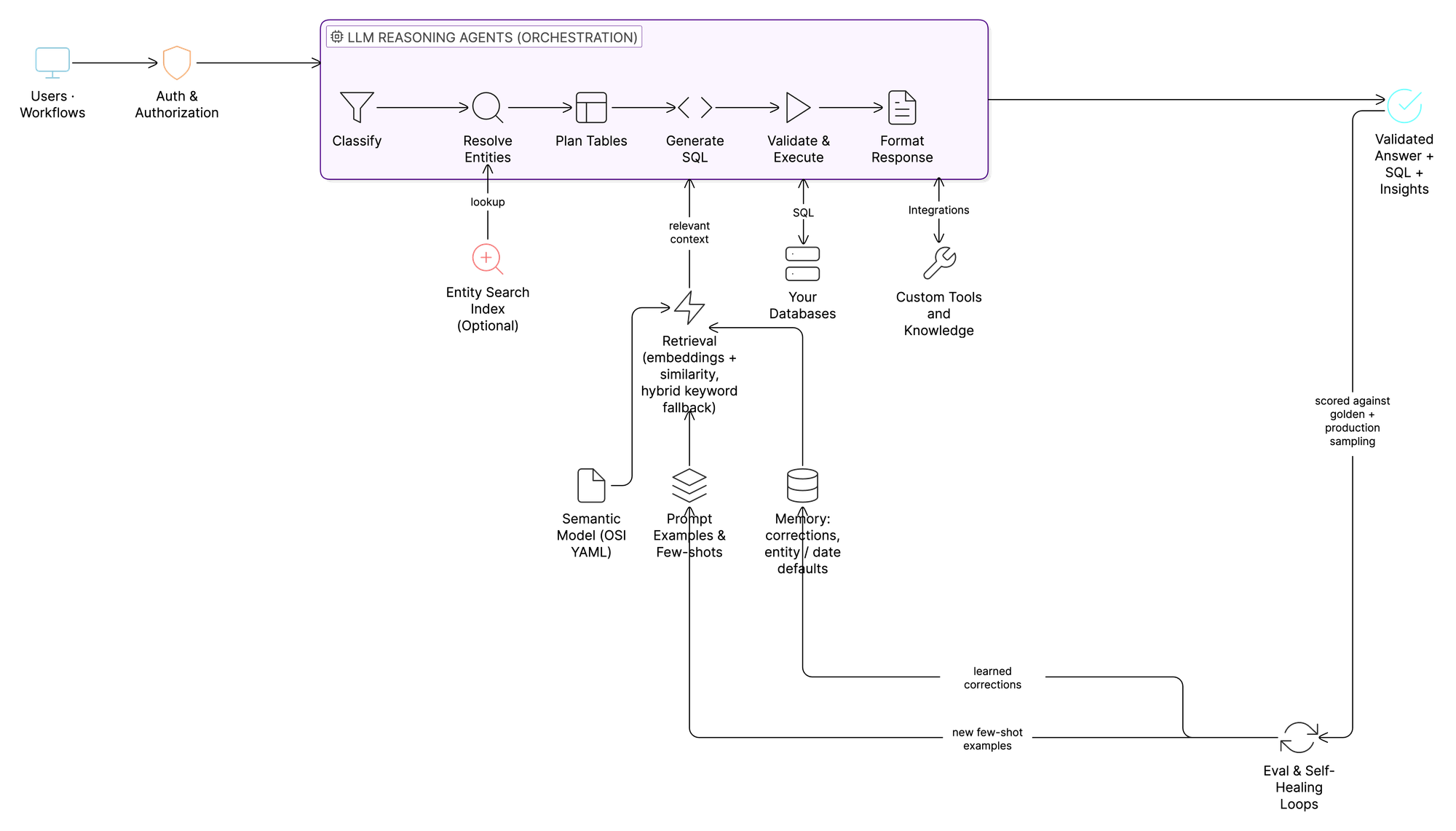
1. Portable semantic model (open standard)
Your business logic, encoded once, portable forever. A YAML semantic model that encodes business definitions, entity types, measure logic, foreign-key relationships, and choice-field enums. Aligned to the Open Semantic Interchange so the same model carries across BI tools, warehouses, and other agents without rewriting. Version-controlled in your git, deployed to your runtime. The model is yours.
2. Retrieval (the index that decides what context the LLM gets)
The right slice of context, in the prompt, every time. The semantic model has thousands of tables, columns, measures, prior queries, and past corrections. The LLM can't see all of it, and dumping everything in would drown the signal. A retrieval layer (embeddings + similarity scoring, with hybrid keyword fallback for exact-match terms like product codes) decides which slices of context land in the prompt. This is where recall/precision trade-offs live, embedding-model choice matters, and indexing strategy quietly shapes agent behavior.
3. Reasoning agents
Multi-stage agents that compound the LLM's strengths and contain its weaknesses. Specialized agents working in sequence: classify the question, resolve the entities it mentions, plan which tables to join, generate SQL in the right dialect, validate it, execute it, and format the response. Each stage gets rich context from the prior ones (via the retrieval layer above), and each is independently improvable. Crucially, the reasoning is done by a frontier LLM (Claude, GPT, Gemini). We don't ship a custom model. We ship the orchestration around one.
4. Memory
The agent that remembers gets a year smarter every year. Every correction is captured as a structured memory entry: a metric was redefined, "last quarter" means our fiscal calendar, "active customers" excludes the trial cohort. Entries are scoped (per-org by default, with per-user overrides for individual preferences) and retrieved by question-intent similarity at the next query, not blindly injected. Conflicts (fiscal vs. calendar Q1, "active" with vs. without trial cohort) resolve by scope precedence and recency: more specific scope wins; within a scope, the most recent correction supersedes older ones. Over weeks the memory thickens. This is what turns a fluent demo into a colleague who has been around six months.
5. Continuous evaluation and self-healing
Wrong answers become training. The system learns in production. Every production query is scored across SQL correctness, output quality, relevance, and entity accuracy. Failures are mined as learned corrections: small structured few-shots retrieved by question-intent similarity at the next similar query. Wrong answer → learned correction → the same mistake is materially less likely to repeat. No fine-tuning, no code deploy, just a thicker context layer that compounds. LLM upgrades are gated on a golden-eval pass: a regressing model is held until prompt-level adjustments resolve the regressions. The truthful word for this isn't "automatic," it's "managed via the eval loop."
6. Production observability
Day one demos look great. Month-six telemetry tells the truth. Every query, every stage, every prompt, every token is captured and queryable. You can see exactly what the agent did, how long each stage took, what the evaluator said, and where accuracy is drifting. Month-six telemetry is what separates a working system from a working demo.
7. Entity search index (Agami enterprise)
The hard cases (Acme vs. Acme Inc.) where pure-LLM approaches quietly fall apart. "Show me Acme Corp's tickets" has exactly one right answer. We don't ask the LLM to guess what your customer is named. We build a search index over your entities (customers, products, employees, projects) and use it for fast, scored lookups inside the reasoning loop, including handling for the hard cases (multiple matches, misspellings, abbreviations, partial matches) that gloss over in pure-LLM approaches. This is the single most expensive thing to get right in production at enterprise scale, and it's the one component we offer commercially rather than as an open skill, because the value is in the integration, the tuning, and the ongoing support, not the algorithm.
We'll publish the rest of the stack (response builder, dashboards, on-prem packaging) as the series progresses, but those are extensions of the seven above, not category-defining on their own.
What's coming next in this series
Each follow-up post goes deep on one part of the architecture, and where it makes sense, lands alongside an open-source skill that puts that architecture into practice. A single skill usually exercises several components at once.
- The portable semantic model. Skill: introspect your warehouse and generate a starter model. Components exercised: Semantic Model.
- Retrieval: the index that decides what context the LLM gets. How embeddings, hybrid keyword fallback, and indexing strategy quietly shape agent behavior. Components exercised: Retrieval, Semantic Model.
- Reasoning agents on top of your data. Skill: query your database in natural language from inside any skill-compatible agent runtime. Components exercised: Reasoning Agents, Retrieval, Semantic Model, Memory.
- Memory: how the agent gets smarter every quarter. Entry shapes, scoping rules, retrieval, and how conflicts resolve. Components exercised: Memory, Retrieval.
- Continuous evaluation and self-healing. Skill: run golden evaluations and harvest learned corrections. Components exercised: Continuous Evaluation, Memory.
- Production telemetry: day one vs. month six. Regression vs drift, golden eval vs production-traffic sampling, the metrics that matter at month six.
- Production entity resolution at scale. (Enterprise deep-dive on the entity search index.)
Buy a CRM. Own your data agent.
Want to follow along? Subscribe and you'll get each post and the open-source skill that lands with it as the series ships.
Want to see it on real data? Book a demo and we'll run the assembled product against your enterprise data.