The query we refuse to run
A fan trap or chasm trap can inflate an aggregate by 3x and nothing errors. Here is how our Analytics Agent detects the hazard from join cardinality and refuses to ship the wrong number.
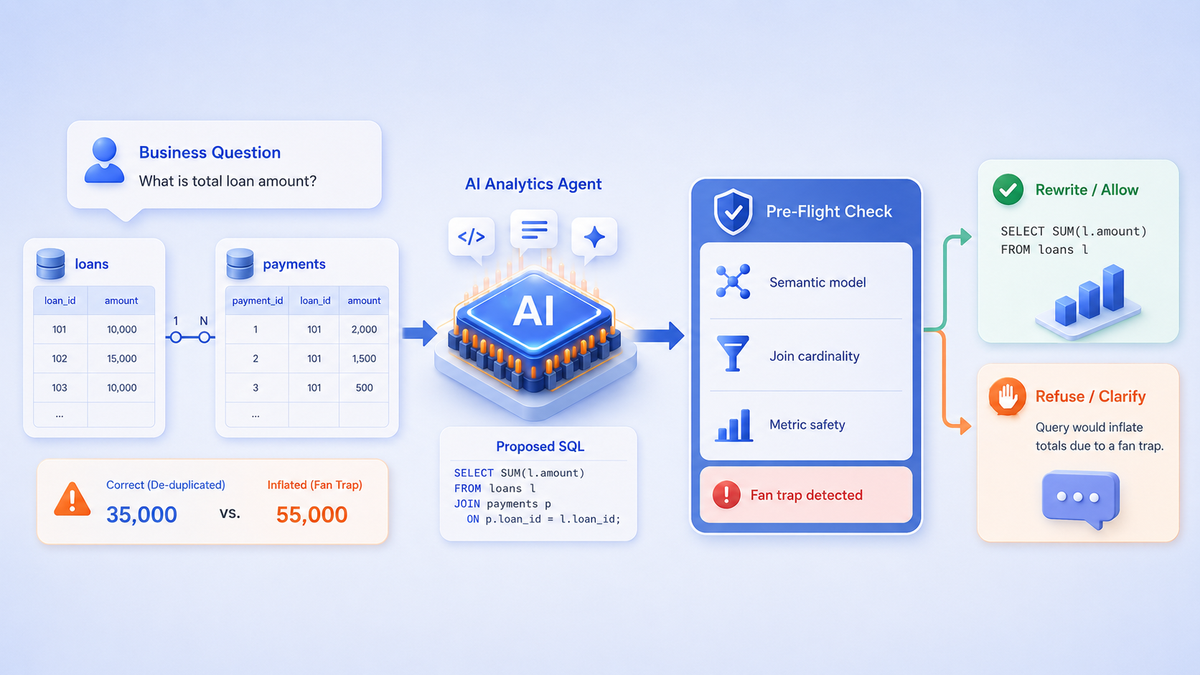
An analytics agent that sometimes says "I cannot answer this the way you asked" is more trustworthy than one that always returns a number. Here is the fan trap, the chasm trap, and why we built a pre-flight that refuses.
TL;DR · fan trap chasm trap, caught before execution
- A fan trap (aggregating a measure across a one-to-many join) and its cousin the chasm trap (two measures sharing a dimension) inflate a total with no error. The query is valid, the schema is valid, and the number is quietly wrong.
- A language model makes this more likely, not less. Grain is not visible in the prompt, so the model writes the inflated query with perfect syntax and total confidence.
- We do not trust the model to avoid it. Before any generated SQL runs, a pre-flight reads the join cardinality from the semantic model, parses the SQL, and either rewrites the query when there is one correct answer or refuses and tells you why when there is not.
"9x% accuracy on your data questions...no hallucinations".
Every AI analytics company flashes a number like that on their website. Almost none will show you the verification behind it. Here is what the remaining Y% looks like: your board deck says $4.8M in revenue, the real number is $1.2M.
Nothing errored, nothing warned, and the query that produced it ran cleanly. The bug has a name, in fact two: the fan trap and the chasm trap. Data engineers have known about both for thirty years, and they still ship to board decks every quarter because nothing about the SQL looks wrong.
This is the most dangerous bug in analytics: the one that looks like an answer.
How a SUM triples itself
Say you have two tables. loans has one row per loan:
| loan_id | amount |
|---|---|
| 1 | 10,000 |
| 2 | 25,000 |
And payments has one row per payment against a loan, so many rows per loan:
| payment_id | loan_id | paid |
|---|---|---|
| 100 | 1 | 500 |
| 101 | 1 | 500 |
| 102 | 1 | 500 |
| 103 | 2 | 1,000 |
Someone asks: "what is the total amount we have loaned out?" The honest answer is 10,000 plus 25,000, which is 35,000.
But suppose the query joins loans to payments along the way, maybe because the question mentioned payments earlier in the conversation, maybe because the join was already in scope:
SELECT SUM(l.amount)
FROM loans l
JOIN payments p ON p.loan_id = l.loan_idThe join expands loans. Loan 1 now appears three times, once per payment, and loan 2 appears once. So the query returns 10,000 times 3 plus 25,000, which is 55,000. The measure got multiplied by the number of rows on the many side.
That is a fan trap: you aggregate a measure that lives on the one side of a one-to-many join, and the join fans the rows out before the SUM sees them. Its cousin, the chasm trap, is worse. Two independent fact tables both join a shared dimension, and each inflates the other into a cross product.
Neither produces an error. Both produce a number. That is what makes them lethal in a BI context: the failure mode is a confident, plausible, wrong total. The query is valid, the schema is valid, and the bug only exists relative to the grain of each table, which is information that lives in the modeler's head and not in the query text.
Why an LLM makes this worse, not better
Hand text-to-SQL to a language model and the failure gets more likely, not less.
A model is trained to be helpful and fluent. Ask it for "total loaned out, and how that relates to payments," and it will happily write a query that joins both tables and sums the amount, because that query looks like what you asked for and it runs. The model has no concept of grain unless you give it one. It will reproduce the thirty-year-old bug with perfect syntax and total confidence, faster than a human could.
So the interesting engineering question is not "how do we prompt the model to avoid fan traps". Prompting will not reliably do it, because grain is not a property of the text. The question is: can we catch the hazard structurally, after the SQL is generated but before it runs, using something we know for certain about the schema? We can. We know the cardinality of every join.
Cardinality is the gate
When the semantic model is built, every relationship between two tables is annotated with its join cardinality (many_to_one, one_to_many, or one_to_one), inferred from the table grains. This is not guessed at query time. It is a structural fact decided once, at introspection, and stored on the relationship.
That single field is enough. Before any generated SQL runs, it goes through a pre-flight that parses the query, finds what is being aggregated, and cross-references the cardinality of every join in scope. The whole thing runs on the SQL abstract syntax tree (AST):
def pre_flight_check(sql: str, org: Organization) -> PreFlightResult:
"""Detect fan-trap / chasm-trap and decide rewrite-vs-refuse-vs-allow."""
tree = sqlglot.parse_one(sql, error_level="ignore")
rels = _cardinality_index(org) # every relationship + its cardinality
tables_in_scope = _tables_in_scope(tree) # alias -> table
agg_sources = _aggregate_source_tables(tree, tables_in_scope) # tables summed/avg'dagg_sources is the set of tables whose columns appear inside an aggregate function. That is the crux: we do not care which tables are joined, we care which table the SUM is reaching into. From there the logic reads straight off the definition of the hazard. No aggregation means no trap. Two aggregate sources sharing a dimension is a chasm trap. One aggregate source sitting on the one side of a one-to-many that is also in scope, is a fan trap.
Notice what this does not do. It does not run the query and check for suspicious row counts. It does not sample data. It does not ask the model "are you sure?" It reads a structural fact, cardinality, off the model and applies the textbook definition of the hazard to the query syntax tree. It is deterministic, cheap, and it runs every single time before execution.
Rewrite when you can, refuse when you can't
Detecting the trap is half the work. The more interesting half is what to do about it, and the answer is not "always refuse."
Sometimes the fan-out join is simply redundant. If the query is aggregation-only and the many-side table is only present in the FROM or JOIN, never referenced in the SELECT, WHERE, GROUP BY, HAVING, or ORDER BY, then the join changes nothing except the row multiplier. We can drop it and the result shape is identical, just correct. In our loans example, the agent silently drops the payments join, sums loans.amount cleanly, returns 35,000, and notes in the receipt that it rewrote the query and why.
But when the many side is load-bearing, there is no safe rewrite that preserves what the user asked for. The agent refuses, and hands back the shape of the query that would be right:
return PreFlightResult(
"chasm_trap",
"refuse",
sql,
reason="independent measures both join a shared dimension; "
"the cross-product inflates both aggregates.",
suggestion="Compute each measure in its own CTE pre-aggregated by the "
"shared dimension, then outer-join the CTEs on it.",
)This is the line most tools will not cross. Refusing feels like failure. You asked a question and got no number. But a refusal with a reason and a fix is strictly more useful than a wrong number with neither. One of them you can act on. The other you ship to your CEO.
"But why not just fix it?"
The obvious objection: if you can detect the trap, why ever refuse? Why not always rewrite?
We do rewrite, when there is exactly one right answer. Dropping a redundant join is mechanical and unambiguous. The reason we do not always rewrite is that when the fan-out join is load-bearing, there is not one correct query. There are several, and they return different numbers. Take the case where the join is also a filter:
SELECT SUM(l.amount)
FROM loans l
JOIN payments p ON p.loan_id = l.loan_id
WHERE p.paid_date > '2024-01-01'We cannot drop the payments join. It is selecting which loans count. But the SUM still triple-counts a loan with three qualifying payments. So what did you actually mean? The total amount of loans that have at least one payment since January (de-duplicate with an EXISTS)? Or something weighted by payment count? Those are different numbers, and the SQL no longer tells us which one you wanted. If we silently pick one and run it, we are right back to handing you a confident number you never asked for, which is the exact bug this whole feature exists to kill. A wrong auto-fix is worse than a refusal, because it is invisible again. A refusal is loud; a bad rewrite looks identical to a good one.
So the agent branches. When the rebuild is unambiguous (the chasm-trap case, where each measure splits cleanly into its own pre-aggregated CTE) it rebuilds the query, runs it, and tells you it did, so you see the restructuring rather than a silent swap. When the rebuild is ambiguous it does not pick for you. It asks: "Did you mean loans with at least one payment since January, or a payment-weighted total?" You choose, and it generates that one. Either way you still get your answer. You just get the right one, from a query that was rebuilt or one you disambiguated, never one that was quietly fudged.
We do not trust the model to avoid the bug, because grain is not visible in the prompt. We encode the one thing we know for certain, the cardinality of every join, and we let that fact veto the query before it touches your database.
Governance does not live in the prompt
It is easy to put "trustworthy AI for analytics" on a landing page. It is harder to point at the specific class of wrong answer you have decided you will never return.
The fan-trap check is one of those points, and it is an instance of a broader principle we hold across the product: governance does not live in the prompt. A rule you write into a system prompt is a rule the model can be argued out of. A rule encoded in the tool the model has to call is one it cannot. The pre-flight is not advice we give the model; it is a gate the generated SQL has to pass before execution. That is what AI you can audit means in practice. A reviewer can read the check, reproduce its decision, and trust that it fired, because it is code, not a suggestion.
The same discipline shows up in how we measure quality. Accuracy you can measure is not a marketing number; it is the fan-trap case sitting in our golden datasets, so a change that lets an inflated SUM through is a regression the eval catches. The model proposes. A deterministic check rooted in the semantic model disposes. Sometimes that means a silent, correct rewrite. Sometimes it means the agent looks you in the eye and says "not like that."
A number you can trust is worth more than a number you get instantly. The query we refuse to run is the feature. If you want the deeper background on why the semantic model is the right home for this kind of structural fact, we wrote about that in The Semantic Model Is Having Its Moment, and the broader pattern of moving guardrails out of the prompt is the subject of Why naive prompting isn't a data agent.
Frequently asked questions
Q: What is a fan trap in SQL?
A: A fan trap is when you aggregate a measure that lives on the one side of a one-to-many join while the many side is also in the query. The join multiplies the rows before the aggregate runs, so a SUM or COUNT comes back inflated. The SQL is valid and no error fires; the number is just wrong.
Q: What is the difference between a fan trap and a chasm trap?
A: A fan trap involves a single one-to-many join inflating a measure. A chasm trap involves two independent fact tables that both join a shared dimension; the cross-product between them inflates both aggregates at once. Both are detected from join cardinality before execution.
Q: Why does an AI text-to-SQL tool make fan traps more likely?
A: A language model writes fluent, plausible SQL, but grain (which table a measure lives on, and the cardinality of each join) is not visible in the prompt. The model will join two tables and sum a column because that matches the question, with no awareness that the join inflates the measure.
Q: How do you detect a fan trap without running the query?
A: The semantic model stores the cardinality of every join. A pre-flight parses the generated SQL into an abstract syntax tree, finds which table each aggregate reaches into, and checks it against that cardinality. It is deterministic and runs before execution, so no data is touched to make the decision.
Q: Why refuse instead of auto-fixing the query?
A: When the fan-out join is redundant there is one correct rewrite and the agent applies it silently. When the join is load-bearing (it filters or groups the data) there is more than one correct query and they return different numbers. Rather than silently guess, the agent rebuilds when the answer is unambiguous and asks a clarifying question when it is not.